Bei der LokaliCon (dem Treffen der Lokalen Community-Raeume von Wikipedia-Aktiven) letztes Wochenende konnte leider niemand vom Lokal K aus Koeln dabei sein, derweil ich wirklich seit Jahren fasziniert beobachte, was die alles machen. Das soll nicht heissen, dass die anderen Raeume nichts oder zu wenig taeten, nur um das klarzustellen – mit Drohnen– und Objektfotografie machen die Koelner*innen aber Dinge, die sehr gut mit meinen Interessen resonieren 🙂
Und ich bin damit nicht der einzige: Mindestens ein nicht genanntes ehemaliges Vorstandsmitglied des temporaerhaus e.V. hat sich bei einer vergangenen Beschaffungsrunde sehr fuer eine eigene Fotodrohne eingesetzt, wofuer ich ihm mittlerweile auch sehr dankbar bin und kaum abwarten kann, Bau- und Bodendenkmaeler in der Region abzulichten. Denn das ist die Idee hinter all dem: Gemeinschaftlich Bilder unter Freier Lizenz anzufertigen, die dann beispielsweise in der Wikipedia verwendet werden koennen – oder wo auch immer, solange die Lizenz eingehalten wird.
Die Koelner*innen dokumentieren derweil auch alle moeglichen technischen Geraete und zerlegen die dafuer sogar, was ich ganz witzig und auch wichtig finde: Viel zu oft landen Dinge einfach auf dem Schrott, wenn sie ihre Nuetzlichkeit verloren haben und oft faellt dann erst Jahre spaeter auf, dass es von bestimmten Artefakten entweder gar keine Fotos gibt oder keine unter Freier Lizenz. Ich war 2020 sehr haeufig damit beschaeftigt, eine jahrzehntelang aufgebaute und komplett unsortierte Technik-Sammlung mit loser Schrott-Beimischung aufzuloesen, wo zwischen buchstaeblichen Stapeln direkt entsorgbarer Allerweltsdinge wirkliche Seltenheiten lagen. Da sind immer noch Dinge dabei, die genau in solche Objektfotografiesessions passen wuerden.
Recht unvermittelt ergab sich jetzt die Gelegenheit, auch mal das mit der Objektfotografie selbst auszuprobieren. Bei irgendeinem Wikipedia-Rabbit-Hole bin ich auf den Artikel zum SCA-System gestossen, einem zuletzt nur noch vom Blitzgeraetehersteller Metz verwendeten Universal-Adaptersystem fuer Blitzgeraete. Der Artikel hatte keine Bebilderung – und weil ich Mitte der 2000er sehr auf den Strobist-Zug aufgesprungen war, liegen bei mir bis heute Metz-Blitze und diverse SCA-Adapter herum. Also machte ich mich gestern auf ins temporaerhaus und wollte eigentlich mit den 45er-CT-Blitzen und Blitzschirmen SCA-Adapter fotografieren – die dicken Blitze waren aber nun offenbar viel zu viele Jahre nur in Kisten herumgelegen und liessen sich nicht zur Arbeit ueberreden. Also wurden diese ersten Bilder mit einer Videoleuchte improvisiert beleuchtet und sehr wackelig mit der Panasonic-Kamera des Vereins fotografiert.
Das hat Lust auf Mehr gemacht! Erster Schritt war nun erst einmal, mich um meine alten Blitze zu kuemmern um herauszufinden, ob die sich fuer diese Zwecke wiederbeleben lassen. Ein 45er-Metz laedt und blitzt nun wieder, der andere laedt nur und loest nicht aus – aber ich habe ja noch den klassischen Strobist-Blitz SB-26 herumliegen. Und eine Hohlkehle wird sich auch schnell im Hausi improvisieren lassen. Dann bekommt mein ab 2006 angesammeltes Blitz-Zeug auch nochmal eine Nutzung, ohne dass man es nur vor der Verschrottung nochmal ablichten muss 🙂
Nebenbei spannend, ich sah eben erst, dass David Hobby 2021 Strobist.com nach 15 Jahren als Projekt beendet hat. Meine ersten Strobist-Style-Fotos sind vom Sommer 2006, d.h. ich muss das Blog innerhalb eines Vierteljahrs nach Entstehen entdeckt und haben und dem sofort verfallen sein, inklusive von mir angeleierter Sammelbestellung der damals in Europa nicht erhaeltlichen Westcott-Falt-Schirme mit diversen Fotojournos. Das Web war wohl kleiner damals. Interessant auch, dass viele der Fotos aus der damaligen Community jetzt etwas ueberholt und nach „typisch 2000er“ aussehen, so wie auch die damals total modernen Slides im ersten Presentation-Zen-Buch, frosted tips oder duenne Augenbrauen.
Dieser Tage fragte mich wieder mal jemand, wann eigentlich das „staedtische Verschwoerhaus“ nun offen sei – weil das naemlich gar nicht so einfach herauszubekommen ist. Wir erinnern uns: Die Ehrenamtscommunity, aus deren Mitte die Idee fuer so einen durch die Kommune angeschobenen Make- und Hackspace kam, wurde im Sommer 2022 aufgrund diverser Kleingeistigkeiten von der Stadt aus den von ihnen aufgebauten Raeumen geworfen. Die Stadt hat der Community dann auch den von ihnen ausgedachten Namen weggeklagt und sich 2023 auch noch der von den Aktiven registrieten Domains bemaechtigt, die eigentlich vom Urteil gar nicht betroffen war, wo der staedtische Anwalt (und CDU-Fraktionsvorsitzende) aber die Moeglichkeit einer persoenlichen Haftbarkeit des Vorstands ueber 250.000 EUR sehr wirkungsvoll gespielt hat.
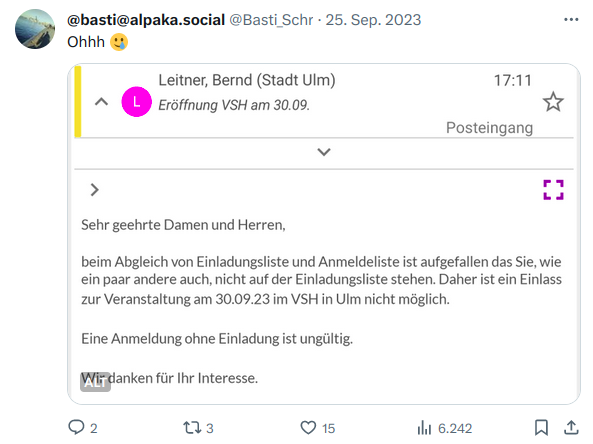
Offenes Haus, aber nur fuer geladene Gaeste: Diverse Leute, die jahrelang zum Inhalt der alten Raeume beigetragen hatten, wurden von der Eroeffnungsfeier wieder ausgeladen. Bei der Feier sorgte offenbar ein Sicherheitsdienst an der Tuer dafuer, dass nur geladene Gaeste reinkamen (Originaltweet)
Diese staedtische Website zum „Verschwoerhaus“ wurde in der Zwischenzeit mehrfach mit immer neuen Ankuendigungen ausgebaut und zwischenzeitlich wieder geleert. Und beinahe haette ich die aktuelle Ankuendigungsseite einfach so ueberlesen, wenn mich nicht jemand auf einen lustigen Passus hingewiesen haette:
Das Verschwörhaus ist für alle Altersgruppen offen als ‚dritter Raum‘, ohne Konsumzwang und mit flexiblen Öffnungszeiten.
Das finde ich ein wenig lustig, denn wie es so schoen heisst, Imitation is the sincerest form of flattery. Andererseits hat mich das ein wenig animiert, die Ankuendigungen der Stadt seit 2022 ein wenig mit dem gegenueberzustellen, was tatsaechlich passiert ist. Und natuerlich damit, was die Ehrenamtscommunity seither auf die Beine gestellt hat.
Was wurde am Weinhof ueberhaupt umgesetzt?
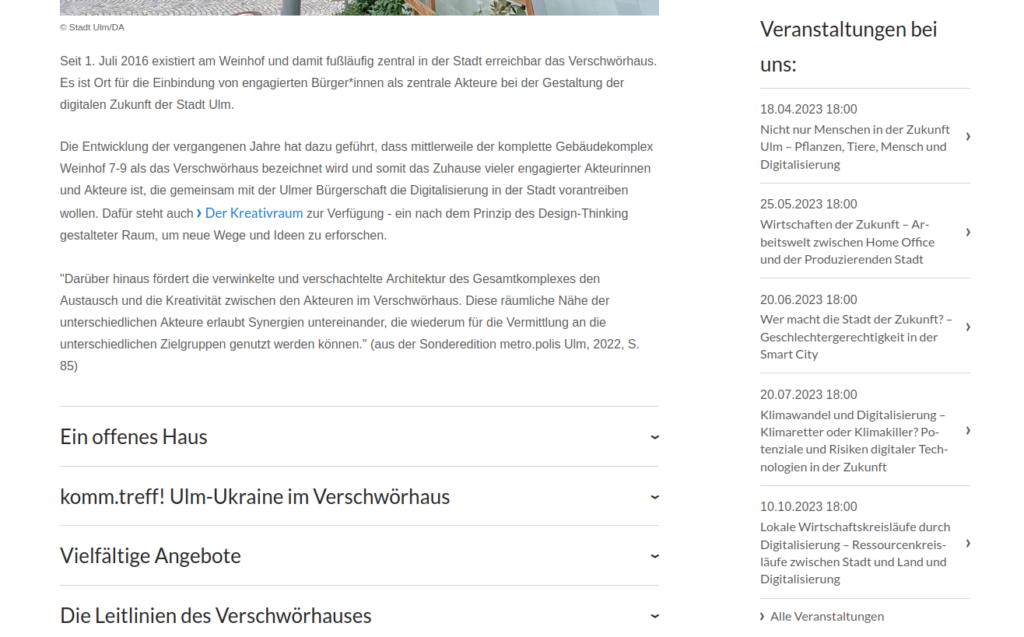
Im Sommer 2022 wurde – moeglicherweise in Vorbereitung des Rechtsstreits – die staedtische Website angepasst (Archivlink, evtl. mit Adblocker eine Blockier-Regel fuer das Cookie-Consent-Banner erstellen), auf der unter anderem behauptet wurde, dass mittlerweile der gesamte Gebaeudekomplex als Verschwoerhaus bezeichnet werde[citation needed]. Spannend sind hier die Ueberschriften „ein offenes Haus“, „Offene & vielfaeltige Angebote“ und „Das geht im Verschwoerhaus“. Der Punkt mit dem Offenen Haus verschwand zwischen Mai und Juni 2023 (dazu spaeter mehr), die anderen dann im Januar 2024.
Ab dem Sommer 2022 schien die Stadt im ausgeraeumten Haus selber vor allem interne Workshops rund um die Zukunftsstadt-Projekte im Haus zu veranstalten. In einer Auflistung, die die Stadt nach einer Anfrage nach dem Informationsfreiheitsgesetz herausgab, finden sich vorwiegend zahlreiche Dubletten zu Veranstaltungen für Ukraine-Geflüchtete – einem Programm, für das die Stadt auf Basis eines noch Anfang 2022 binnen 48 Stunden von den Ehrenamtlichen aus dem Boden gestampften Internetcafés und der allein bei der Ehrenamtsstruktur liegenden Erfahrungen mit Programmen wie Jugend hackt beim Staatsministerium eine Förderung fuer einen ebenfalls im Haus befindlichen Verein eingeworben hatte. Neben dem noch vom ehemaligen Verschwörhaus-Verein bepielten Jugend hackt Lab findet sich ansonsten in der Auflistung vor Allem eine Swingtanzgruppe als Angebot des „Offenen Haus“ – deren Angebote sich aber nie auf der Website der Stadt wieder fanden.
Erfolgsvergleich: Was war 2023 angekuendigt?
Rueckblickend sehr spannend ist auch die Gegenueberstellung der Ankuendigungen, die im Januar 2023 in einem Artikel der Suedwest Presse (Paywall) vom staedtischen „Verschwoerhaus“ und der aktiven Ehrenamtscommunity aufgezaehlt wurden. Der damals bereits knapp acht Monate arbeitende hauptamtliche staedtische Leiter wird im Artikel mit folgenden Zielen zitiert:
Es stehe „ein Audio- und ein Videolabor zur Verfügung“
der „Makerspace im Untergeschoss [solle] wieder öffnen“
„Steht auch das geplante Buchungssystem, so solle die Werkstatt rund um die Uhr und täglich geöffnet sein“
„Bis Ende Januar werde er zudem ein Veranstaltungsprogramm fertig haben und vorstellen.“
„Fast jeden Tag soll etwas los sein im Verschwörhaus.“
Realitaetscheck: kein einziges dieser Ziele wurde bis Ende 2023 ernsthaft erreicht. Zu mehreren der Punkte passierte nichts erkennbares.
Zu Jugend hackt: Das war gleichermaßen ambitioniert wie realitaetsfremd. Zur Erinnerung: Die Jugend-hackt-Hackathons wurden ausgehend von der Vernetzung mit der Open Knowledge Foundation Deutschland seit derer Gruendung von der oertlichen Ehrenamtscommunity ab 2014 vorbereitet und 2015 als regionaler Ableger von der Community zunaechst an der Uni durchgefuehrt – und beim ersten Jugend hackt in Ulm entstand der Vorschlag an den damaligen OB-Kandidaten Czisch, doch einen staedtisch gefoerderten Ort fuer den Aufbau von Civic Tech und den Wissenstransfer aus der Ehrenamtscommunity in die Verwaltung aufzubauen. Dass die Stadt einerseits die engagierte Community rauswerfen und dennoch Jugend hackt unter ihrem Banner weiter betreiben werden duerfe, war von Anfang an eine total absurde Annahme. Im Maerz 2023 kuendigten die staedtischen Hauptamtlichen an, kuenftig alternativ „Ulm hackt“ anbieten zu wollen (Paywall). Im gesamten Jahr 2023 passierte dergleichen: Absolut nichts.
Zum Audio- und Videolabor: Ab dem Spaetsommer 2016 hatten die Aktiven am Weinhof mit den staedtischen Mitteln – von denen sie nach dem Zitat von Gunter Czisch darauf vertrauten, dass sie fuer den Aufbau ihres Orts sein wuerden, zu dem die Stadt nur den Anschub finanziere – ein Audio- und Video-Setup nach dem Vorbild des VOC des CCC aufgebaut, mit dem sie verschiedenste Veranstaltungen aufgezeichnet und live gestreamt hatten – teilweise auch als von der Digitalen Agenda in Anspruch genommene Community, um deren Veranstaltungen gratis mehr Oeffentlichkeit zu verschaffen. Durch den Gluecksgriff einer Foerderung durch die Deutsche Stiftung fuer Engagement und Ehrenamt Ende 2021 konnte der Verein das bestehende, durch staedtische Mittel beschaffte Audio- und Videosetup zwar durch eigene Geraete ergaenzen und signifikant upgraden. Das bis dahin aufgebaute und der Stadt gehoerende Setup fuer Videostreams und Podcasts vergammelte aber offenbar das gesamte Jahr 2023 ueber mangels Kompetenzen fuer dessen Bedienung in den Schraenken am Weinhof. Waehrend das Temporaerhaus einen Livestream fuer die Eroeffnung des SpoSo-Gebaeudes gemeinsam mit dem Haus der Nachhaltigkeit anbieten konnte, gab es von der exklusiven, nicht-oeffentlichen Wiedereroeffnung des Weinhofs ueber ein Jahr nach dem Auszug der Ehrenamtlichen(!) im September 2023 nur eine Pressemitteilung. Auf der aktuellen Fassung der staedtischen Website vom Januar 2024 steht immer noch die Ankuendigung eines Audio- und Videolabors (das laut Pressebericht vom Januar 2023 angeblich schon zur Verfuegung stehe). Ansonsten: Nichts.
Zum Makerspace und dem Buchungssystem: Ja, ernsthaft, keine Ahnung. Makerspace und Holzwerkstatt sind mit die am meisten nachgefragten Angebote im temporaerhaus seit dessen Wiedereroeffnung in Neu-Ulm. Die Nachfrage sowohl nach 3D-Druck als auch nach Lasercut als auch nach der Holzwerkstatt ist riesig. Am Weinhof hatte die Community zwei 3D-Drucker, einen Lasercutter samt Absaugung und eine ueber die Jahre und die Erfahrung krass gewachsene Holzwerkstatt u.A. mit Formatkreissaege, Dickenhobel und Bandsaege hinterlassen. Was die Stadt daraus bisher gemacht hat ist komplett raetselhaft. Der Presse hatte ich entnommen, dass die bisherige Holzwerkstatt im Keller und der Makespace im Erdgeschoss ausgebaut und per Chipkarte zugaenglich gemacht werden sollen, so dass sie „rund um die Uhr und taeglich geoeffnet sein“ solle. Erkennbar war davon Ende des Jahres 2023: Nichts. Was von den urspruenglichen, von den Ehrenamtlichen ausgewaehlten und aus staedtischen Mitteln beschafften Geraeten am Weinhof zugaenglich ist und wann man diese nutzen kann: Komplett unklar.
Zustand im Maerz: Fuenf Veranstaltungen in den kommenden sieben Monaten.
Zum Veranstaltungsprogramm: Das habe ich ehrlich gesagt auch immer wieder gesucht. Den Akteuren bei der Stadt schien es 2023 wichtiger zu sein, beispielsweise das Urteil des Landgerichts zur Markenrechtsentscheidung in die Seitenleiste der staedtischen Website zu verpacken, als tatsaechliches Angebot des „offenen Haus“ fuer die allgemeine interessierte Oeffentlichkeit zu organisieren und dazu die Oeffentlichkeit auch einzuladen. Nach Auskunft einer weiteren Anfrage nach dem Informationsfreiheitsgesetz bestand das Angebot des „Offenen Haus“ in der ersten Haelfte 2023 vor allem – sehr dublettenbehaftet – in dem im Dokument so genannten „Ukraine-Projekt“ sowie einer Swingtanzgruppe und einem Angebot des Generationentreffs – nichts davon war vorab auf der staedtischen Website ueber das „Verschwoerhaus“ angekuendigt. Stichproben aus dem Internet-Archiv zeigen diverse Smart-City-Veranstaltungen und sonstige interne Veranstaltungen der Digitalen Agenda sowie interne Workshops der Stadtverwaltung. Weitere nicht oeffentlich angekuendigte Termine wie eine Vorstandssitzung einer örtlichen Unternehmerinitative vervollstaendigen das Programm – von dem angekuendigten Veranstaltungsprogramm Ende Januar 2023 fuer die allgemeine Oeffentlichkeit ist aber nichts zu erkennen. Auf einem Schnappschuss vom Maerz sind beispielsweise sage und schreibe fuenf Smart-City-Veranstaltungen fuer die kommenden sieben Monate zu sehen – das war’s. Wer wissen wollte, wann man denn die Raeume aufsuchen koennte, sollte wohl bei der Stadt anrufen, man weiss es nicht. Gerne haette ich auch eine Auflistung aller Veranstaltungen seit Juni ausgewertet. Die Digitale Agenda nimmt aber wieder einmal die gesetzlichen Pflichten fuer Antworten auf Informationsfreiheitsanfragen eher locker und ist seit zwei Wochen mit der Antwort im Verzug. Das kennt man ja mittlerweile.
Irgendwer kann hier kein Excel
Zu fast jeden Tag soll etwas los sein: Ja gut. Wenn man alle Dubletten aus der Antwort auf die Informationsfreiheitsanfrage loescht, bleiben von 1.1.2023 bis 09.06.2023 – also einem Zeitraum von 159 Tagen – von 108 angegebenen Terminen nur 91 Termine uebrig. Davon entfallen mit 54 Terminen fast 60% auf das Programm fuer die Ukraine-Gefluechteten. Mit 9 internen Fortbildungen und Terminen der Verwaltung und 8 internen Terminen rund um irgendwelche Smart-City- und Zukunftsstadtprojekte bestand das „Angebot“ zu weiteren knapp 20% einfach aus der Nutzung der Raeume fuer verwaltungsinterne Termine. So richtig fuer alle oeffentliche Termine scheinen in dem Zeitraum weniger als 20% ausgemacht zu haben – ist die Bude also doch eher Vereinsheim fuer ausgewaehlte Gruppen? Auch fuer die Zeit nach Juni finden sich nur vereinzelte Veranstaltungen auf den Schnappschuessen im Internet Archive; beispielsweise ein „Innovationsmotor“, bei dem offenbar technische Loesungen fuer soziale Probleme gefunden werden sollen. Von den im Mai 2022 versprochenen „neuen Gruppen“, fuer die sich das Fakeschwoerhaus oeffnen wolle, ist bislang jedenfalls nichts zu sehen.
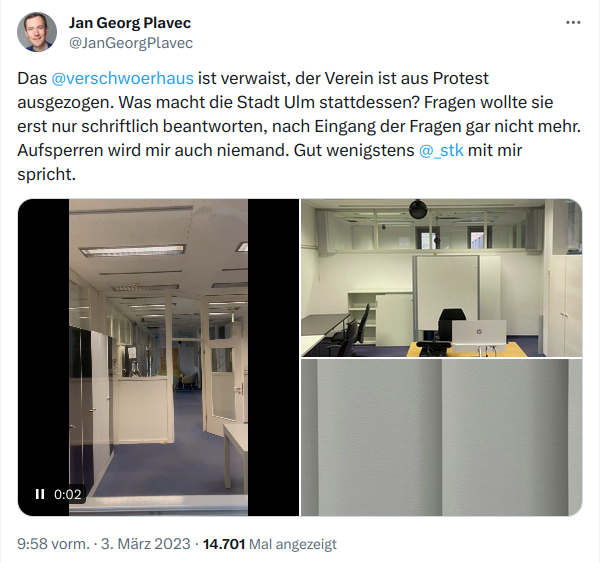
Das lustigste an diesem Tweet ist das durchs Fenster aufgenommene Video der leeren Raeume, waehrend Leuchtstoffroehren so richtig dystopisch vor sich hin flackern
Ob (abgesehen von den Dubletten) auch alle diese Veranstaltungen ueberhaupt stattgefunden haben, bleibt indes unklar – als im Maerz ein Journalist der Stuttgarter Zeitung ueber den Zustand am Weinhof berichten wollte, war das Haus laut Aushang wegen Krankheit geschlossen. Und ueber Wochen hinweg hing im Fruehjahr ein Zettel an der Eingangstuere, dass wegen Umbauarbeiten die Oeffnungszeiten entfallen wuerden. Alle Selbstauskuenfte der Stadt sollten mit Vorsicht genossen werden – auch zu dem Umbau, wie sich bei einem weiteren Blick ins Internet Archive zeigt.
Diese Stufen gilt es zu ueberwinden, wenn man mit Rolli in den Salon kommen und auch aufs barrierefreie Klo und den Rest des Gebaeudes, ohne einmal aussenrum ueber den Hof fahren zu muessen.
Der Umbau und die Barrierefreiheit: Schon im Fruehjahr 2023 war die Bude eine Weile laut Aushang geschlossen, weil Dinge umgebaut werden sollten. Auf der Website stand davon zunaechst nichts, im Endeffekt wurde wohl nochmal ein wenig mehr Innovationslabor-Vibe in den Laden gebracht und offenbar haben sie es dann irgendwann auch geschafft, eigenes WLAN fest zu installieren (was lustig ist, weil das eine chaotische Ehrenamtstruppe 2016 einfach binnen weniger Tage selber hinbekommen hatte). Interessant wird es beim zweiten Umbau, der von Juni bis Oktober 2023 angekuendigt war (Archivlink), offenbar auch um den Weggang des zwischenzeitlichen hauptamtlichen Leiters ueberbruecken zu koennen. Aus dem Absatz zum „offenen Haus“ wurde naemlich ein „Das Verschwoerhaus wird barrierefrei“, und da war ich wirklich neugierig, wie sie das hinbekommen wollen. Der vordere Saal – um den es laut Angaben der Stadt explizit gehen sollte – ist naemlich aus allen Richtungen nur ueber Stufen erreichbar, und da wir Aktive haben, die im Rollstuhl sitzen, war das schon immer ein Problem. Nur war das geometrisch gar nicht so leicht zu loesen. Eine praktikable Loesung muesste eigentlich vom Salon in den „hinteren“ Teil von Weinhof 7 gehen, weil nur so die normgerecht barrierefreie Toilette im 2. OG erreicht werden kann. Eine Rampe mit zulaessiger Steigung waere dort aber gut 5 Meter tief, und wegen der seltsamen Treppe kaemen dort nur aufwaendige Scherenliftkonstruktionen als Alternative in Frage. Wir hatten uns ueber die Jahre immer wieder ueber Alternativen den Kopf zerbrochen, aber auch eine Rampe vom Aquarium her kommend oder ueber das Treppenhaus von Weinhof 9 kommend wuerde eine Sackgasse bedeuten, wenn jemand weiter nach hinten ins Haus wollen wuerde. Der Witz ist jetzt: Ich wuesste immer noch gerne, wie sie das mit der Barrierefreiheit hinbekommen haben. Ich war seit dem Auszugstag im Sommer 2022 nicht mehr in den Raeumen, aber soweit ich das bislang erzaehlt bekommen habe, gibt es den angekuendigten Treppenlift anscheinend gar nicht. Von der Website ist die Ankuendigung zur Eroeffnung auch sang- und klanglos verschwunden.
Fazit: Viel scheint da nicht zu laufen am Weinhof. Obgleich dort mittlerweile offenbar drei hauptamtliche Kraefte arbeiten, fehlt offenbar bis heute die wichtigste Zutat, die solch einen Ort ausmacht und die auch den krankheitsbedingten Ausfall des Hauptamtlichen im Fruehjahr 2023 auffangen haetten koennen: Eine engagierte Ehrenamtscommunity, die den Ort als den ihren begreift und ihn gestaltet. Wie auch, moechte man fast fragen – nachdem sich die verantwortlichen Personen so lange wie tyrannische und intrigante Eltern aufgefuehrt haben, die mit Machtinstrumenten ihren Willen durchzudruecken versucht haben. Das muesste eigentlich auch allen glasklar sein, die auch nur oberflaechlich mit solchen Orten jemals zu tun gehabt hatten, und ein grosser Teil meiner Verhandlungen mit dem OB 2021 bestanden darin, ihm das zu vermitteln und dass eine kritische Begleitung (die auch Innovationstheater hinterfragt) total wertvoll fuer eine Stadt ist. Dass OB und die Leitung der Digitalen Agenda auf die abstruse Idee kamen, das einfach selber hinzubekommen und nicht begriffen haben, dass so etwas ohne die „zwei Hand voll Durchgeknallter“ nicht so wirklich funktioniert, finde ich bis heute absolut wild 😀
Im Januar 2024 wurde nun mit einem Jahr Verspaetung immerhin der Start eines ersten Jugendprogramms unter dem, sagen wir mal, interessanten Titel „Cyberkids“ angekuendigt. Vier Termine bis zum 6. April sind zwar noch weit entfernt von „beinahe jeden Tag“, aber immerhin ueberhaupt einmal etwas oeffentlich angekuendigt zu sehen ist ja schon einmal was, nach ueber eineinhalb Jahren. Nach wie vor werden der Aufbau eines Makespace und eines Podcast-Studios angekuendigt, wo man nur wiederholen kann: Alles von dem angekuendigten Zeug von der Loetwerkstatt ueber 3D-Drucker und Lasercutter bis zur Stickmaschine steht bereits die ganze Zeit seit juli 2022 herum, es muss nur wieder ueber Oeffnungszeiten zugaenglich gemacht werden. 2023 hat das das komplette Jahr nicht geklappt, ich bin mal gespannt auf 2024. Und auch mit der seit irgendwann im September 2023 bei der Stadt liegenden Domain soll nun irgendwas passieren – bei einer Vorzeige-Digitalisierungsabteilung braucht man fuer eine Website wohl einfach mal ein Vierteljahr. Zum Vergleich: Die Ehrenamtlichen hatten sage und schreibe 13 Tage fuer eine eigene Website gebraucht, und nach weniger als eineinhalb Monaten gab es auch eine Anzeige, ob derzeit die Türe offen ist.
Ich kann nur dazu raten, gut Buch ueber die vollmundigen Ankuendigungen zu fuehren und regelmaessig einen Realitaetsabgleich zu machen. Momentan scheint die Stadtspitze keine Nachfragen aus Presse und Gemeinderat zu ihrem PR-durch-Ankuendigungen-Game zu bekommen und gut damit zu fahren. Irgendwann sollten aber schon einmal Fragen kommen, warum jetzt aus oeffentlichen Mittel so viel mehr Aufwand bei vergleichsweise so viel weniger Angebot unterm Strich steht.
Aber vielleicht ist das staedtische Verschwoerhaus ja wirklich ein „Dritter Raum“. Bei dem eingangs beschriebenen Abschreibeversuch vom temporaerhaus scheint es da naemlich einen Uebertragungsfehler vom Dritten Ort gegeben zu haben. Ob das jetzt ein Dritter Raum im Sinne von Homi K. Bhabha sein soll, wo Unterdruecker und Unterdrueckte sich austauschen, oder der hypothetische Dritte Raum im medizinischen Sinn, wohin oeffentliches Geld, aeh, Blutplasma einfach verloren geht, ist nicht ganz klar. Lustig finde ich beide Vorstellungen.
PS: All denen, die in der Vergangenheit Anfragen der Stadt zu Reputation Management bekommen haben (natuerlich immer nur muendlich, nie schriftlich) und alle moeglichen Behauptungen ueber die Ehrenamtscommunity erzaehlt bekommen haben, kann ich nur empfehlen, sich auch eine zweite Meinung von den Aktiven zu holen. Ich bekam teilweise zugetragen, was fuer wilde Spins da im Umlauf sind. Auch das einem Realitaetscheck zu unterziehen ist meist ein grosser Spass fuer alle Beteiligten.
Die Videos des „Akkudoktor“ Andreas Schmitz rund um Klein-Photovoltaikanlagen sind in Teilen meines Bekanntenkreis lange Pflichtprogramm. Da nerdet sich jemand richtig tief ins Thema rein (und ist auch schon vom Fach), testet Geraete tiefer auf Herz und Nieren als so manchem Hersteller das lieb ist und macht das derweil, ohne dabei was verkaufen zu wollen – weil er an den damit verbundenen hoeheren Zielen interessiert ist.
Im oben eingebetteten Video teilt er gute und schlechte Erfahrungen im Umgang mit Herstellern und wie das normalerweise mit Influencern und Influencer-Agenturen so laeuft – und da fiel es mir wie Schuppen aus den Haaren, dass das in weiten Teilen auch Erwartungshaltung sowie Spannungsfeld zwischen zivilgesellschaftlichem Civic-Tech-Einsatz und Verwaltung – und insbesondere Smart City – widerspiegelt.
Als Gold-Standardfall nennt Schmitz, dass es nach einem von ihm gemeldeten Problem sofort eine Krisensitzung gab, die Entwicklungs-/Engineering-Abteilung einbezogen wurde, er offenbar auch direkten Draht dorthin bekam und er die naechsten Schritte dargelegt bekam, was nun zur Fehlerbehebung passieren wuerde. Das Negativbeispiel, das bei Influencermarketing normal sei: Man habe nur Kontakt zu einer Influenceragentur. Die hat gar keinen Durchgriff aufs Produkt und bezahlt einen im Zweifelsfall, dass man gefundene Probleme nicht an die grosse Glocke haengt und die Schnauze haelt.
Kommt bekannt vor? Mir schon. Mit dem spannenden Unterschied, dass es die Entwicklungs- und Engineering-Abteilung z.B. in der Smart City meist nie im eigenen Haus gibt. Und es dementsprechend diesen Feedback- und Lösungs-Cycle gar nicht geben kann. Weil quasi jeder Schmarrn von externen Dienstleistern entwickelt wird – die manchmal brauchbares Requirement Engineering vom oeffentlichen Auftraggeber bekommen. Meist aber nicht.
Bei mancher oeffentlichen Stelle wuerde ich mittlerweile aus der Erfahrung im Austausch mit den an der Sache interessierten zivilgesellschaftlichen Engineers (w/m/d) und der behoerdlich eingerichteten Digitalisierungsagentur mittlerweile auch sagen: Das ist mehr Influencer-Agentur denn an der langfristigen Entwicklung interessierte Einheit. Denn sie sind nicht nur von den zu entwickelnden Produkten und Infrastrukturen so weit weg wie die Influencer-Agentur. Sondern ihnen ist im schlimmsten Fall das langfristige ideelle Ziel weniger wichtig als die akute oeffentlichkeitswirksame Darstellung.
Vor dem Hintergrund bin ich gerade auch etwas professionell angepisst vom neuerlichen Vorstoss der Social Entrepreneurs von ProjectTogether, die heute ihr neues rework-Programm vorstellten, mit dem nun alles bei der Verwaltungsdigitalisierung besser werden soll. Nicht nur, dass mir das gesamte Social-Entrepreneur-Wesen von Grund auf unsympathisch ist – ich halte diese Verlagerung von Verantwortung in Startups fuer Teil des Problems, nicht der Loesung. Dazu kommt, dass die Truppe mir mit UpdateDeutschland noch enorm schlecht in Erinnerung ist. Nach dem Event gab es einen Austausch mit Aktiven des Netzwerks Code for Germany, bei dem in kurzer Zeit immer deutlicher wurde, dass der ganzen Veranstaltung kaum vorbereitende Recherche vorausgegangen war, was es bislang schon gab und was weswegen (nicht) funktioniert hatte.
Ich persoenlich haette schon gerne, dass das mit der Verwaltungsmodernisierung was wird. Wenn dann brauchen wir aber mehr Austausch wie den, den Andreas Schmitz beschreibt. Und in vielen Faellen muss dafuer erst einmal die Entwicklungs- und Engineering-Abteilung im Staat erst mal wieder internalisiert und als wichtig eingeordnet werden, anstatt das weiterhin auf Dienstleister auszulagern. Einfach nur dasselbe Silicon-Valley-Cosplay weiter nachzumachen, wird lediglich auch in Deutschland laengst (mehrfach) abgespielte Playbooks nochmal von vorne auffuehren. Dabei den naechsten Schwung ueberzeugter EnthusiastInnen in den Burnout schicken. Denjenigen, die daraus dann eine Buehne machen, hat das bislang selten geschadet. Ich wuerde aber gerne endlich mal wieder die Sache im Vordergrund sehen.
Je laenger ich Wikidata und die Konzepte von Linked Open Data und was alles dazugehoert kenne, desto faszinierter werde ich davon. Derweil brauchte ich wirklich lang, um das zu verstehen – bei meinem ersten Kontakt 2012 war ich etwas ratlos, die deutschlandweiten Wikidata-Workshops im damaligen Verschwoerhaus ab 2016 haben wir das aber umso naeher gebracht, und spaetestens ab ca. 2019 war ich bei meiner Erkundungswanderung durch die Ulmer Stadtverwaltung ueberzeugt: Wer Open Data haben will, muss Linked Data mitdenken – alles andere ist Augenwischerei.
Leider ist es nicht ganz so leicht, sich in die Thematik einzuarbeiten. Ich habe die letzten Wochen aber zwei Hilfestellungen gefunden, die das vielleicht erleichtern koennten. Das schlimme ist ja, dass man das kaum mehr einschaetzen kann, sobald man selbst nahe genug dran ist – von aussen wirkte alles hoechst kryptisch und verschlossen und unverstaendlich. Hat man die Schwelle aber einmal ueberschritten, ist ja alles klar.
Denny Vrandečić, Lydia Pintscher und Markus Kroetzsch haben auf The Web Conference 2023 ein Paper zur Geschichte von Wikidata veroeffentlicht und es gibt die Inhalte auch in einem unterhaltsamen Video:
Ausserdem laeuft aktuell ein wie ich finde gut gemachter MOOC-Selbstlernkurs des Hasso-Plattner-Instituts zu Knowledge Graphs. Die Teilnahme ist kostenlos, und wer jetzt sofort mitmacht, kann auch noch die bewerteten Zwischenuebungen mitmachen. Was ich bislang gesehen habe, gefaellt mir sehr gut und stellt auch gelungen die Verbindungen zwischen den abstrakten Konzepten von Knowledge Graphs, dem Semantic Web Stack und den urspruenglichen Ideen des Semantic Web her – das ist etwas, was beim 5-Sterne-Modell teilweise zu implizit angenommen wird.
Seit 2019 gab es pandemiebedingt keinen Chaos Communication Congress mehr. Nachdem der Versuch 2022 mit Blick auf die Infektionslage im Spaetherbst abgesagt wurde, steht nun fest:
2023 wird es einen Congress in Hamburg geben
mit Blick auf Covid wird er nur abgesagt werden, wenn er behoerdlich untersagt wird
Das sorgt fuer Veraergerung auf Mastodon, die ich nachvollziehen kann. Wer sich ein teures Ticket ergattert hat, wird sich ggf. bei Husten und moeglicher Infektion ueberlegen, zuhause zu bleiben oder doch hinzugehen, merkt Leah an (gesamte Tootkette in einem Blogpost). Es gibt nicht wenige Menschen im Chaos, die aus gesundheitlichen oder anderen individuellen Gruenden Infektionen tunlichst vermeiden sollten. Und der Congress ist ohnehin quasi „traditionell” ein Ort, an dem nicht nur Geraete, Ideen und Informationen ausgetauscht werden, sondern auch Infektionskrankheiten.
Auf der anderen Seite habe ich Argumentationen gehoert, dass es fuer die organisierenden Menschen nicht umsetzbar sei, Luftfilter fuer 15000 Menschen und Masken und taegliche Tests umzusetzen. Die Argumentationslogik habe ich bislang etwa so verstanden: Die Goldloesung ist nicht machbar und vor allem nicht umsetzbar, deswegen machen wir gar nichts und verweisen auf die behoerdlichen Vorschriften – in denen steht, dass es keine Vorschriften gibt.
Ich habe in Anlehnung an den (von mir wirklich verhassten) Spruch „kein Backup, kein Mitleid“ an einer Stelle „kein Infektionsschutzkonzept, kein Mitleid“ drunterkommentiert. Das passt aber eigentlich nicht ganz, weil das zwei ganz verschiedene Systematiken sind. Und wenn man das aufdroeselt, ist man sehr schnell an des Pudels Kern – der bis zur Hackerethik des CCC und den etwas fragwuerdigen Fuessen der Hackerethik nach Levy zurueckgeht, auf der sie aufbaut.
„Kein Backup, kein Mitleid“ passt naemlich vielmehr konsequent auf ein Infektionsschutzkonzept, das zu 100% auf die Selbstverantwortung von Individuen aufbaut. Jede*r ist fuer die Sicherheit ihres Koerpers genauso verantwortlich wie fuer die Sicherheit ihrer Informationen. Wer das nicht machen moechte, kann das als individuelle Freiheit begreifen – darf sich dann aber nicht beklagen, wenn ein Schaden eintritt.
„Kein Infektionsschutzkonzept, kein Mitleid“ ist eine komplett andere Denkweise. Hier wuerde ein Kollektiv einen Rahmen schaffen, der Risiken zu verringern versucht. Das schliesst die individuelle Verantwortung keineswegs aus. Es verlagert aber einen Teil der Verantwortung vom Individuum auf alle Anwesenden. Und nur der Vollstaendigkeit halber sei erwaehnt, dass meine Datensicherungsmassnahmen natuerlich keineswegs dadurch beeintraechtigt werden, wenn sich meine Geraete in der Gegenwart von tausenden anderen Geraeten befinden, deren Eigentuemer*innen es als ihre individuelle Freiheit betrachten, keine Schutzmassnahmen anzuwenden.
Das ist ein klassischer Konflikt der Hackerethik, den ich spaetestens seit 2016 durch den nach wie vor empfehlenswerten Vortrag „Programming is forgetting: Towards a New Hacker Ethic“ von Allison Parrish auch endlich formulieren kann: Ich kann sowohl die CCC-Ethik wie auch die Levy-Ethik als sehr individualistische, fast schon libertaere Freiheitsrechte interpretieren, oder aber als kollektivistische Aufforderung, gemeinsam eine Welt herzustellen, die sich einem Ideal annaehert. Und leider sind beide Ethiken in ihren Formulierungen naeher an der individuell-libertaeren Lesart. So wundert es auch keinesfalls, dass beide Stroemungen seit jeher in der Szene vertreten sind.
Es lohnt sich wirklich, den Vortrag von Parrish anzusehen oder wenigstens das Transkript zu lesen. Man kann naemlich direkt die klassische Levy-basierte Hackerethik auf den Congress umschreiben – oder eben Parrishs als Fragen vorgestellte Vorschlaege fuer eine Neuformulierung: „Der Zugang zum Congress sollte unbegrenzt und vollstaendig sein“ vs. „wer kann am Congress teilhaben? Wen lasse ich aus? Wie ermögliche oder verhindere ich Zugang?“. „Beurteile einen Hacker nach dem, was er tut, und nicht nach ueblichen Kriterien wie Aussehen, Alter, Herkunft, Spezies, Geschlecht oder gesellschaftliche Stellung“ vs. „Welche Art von Community habe ich als Modell? Welche Community lade ich durch meine Handlungen ein? Wie bilde ich meine Werte in dem ab, was ich mache?“
Ganz besonders moechte ich aber auf den Punkt „Misstraue Autoritaeten – foerdere Dezentralisierung“ eingehen. Parrish fragt hierzu: „Welche Machtsysteme errichte ich durch das, was ich mache? Auf welcher Art von Support verlasse ich mich? Wie unterstützt das, was ich mache, andere Menschen?“
In der Diskussion habe ich naemlich nun mehrfach als Argument gehoert, dass schon bisherige Regeln schwer umsetzbar seien – beispielsweise Rauchverbot oder Fotopolicy. Grundsatz bei Chaosveranstaltungen ist ja, dass Anwesende grundsaetzlich nicht fotografiert werden sollen, wenn sie damit nicht ausdruecklich einverstanden sind. Das geht ueber die gesetzlichen Regelungen weit hinaus. Und auch sonst werden diverseste gesetzliche Regelungen im Chaos und auf den Veranstaltungen durchaus locker ausgelegt.
Ich finde das gerade wirklich enorm faszinierend: Einerseits schafft man sich Freiraeume durch selbst geschaffene Regeln und Wertbilder, die nicht mit denen der Mehrheitsgesellschaft und der allgemeinen gesetzlichen Lage uebereinstimmen. Andererseits wirkte es in der Mastodon-Diskussion immer wieder so, als sei die einzige Moeglichkeit eines Infektionsschutzkonzepts, mit Vorschriften und Pflichten zu arbeiten, die dann auch durch Autoritaetssysteme durchgesetzt werden muessen.
Leah verwies auf Mastodon auf diese Informationsseite der Kiwipycon, die den Umgang mit Infektionsschutz von einem individuellen Selbstschutz hin zu einem Ziel gemeinschaftlicher Anstrengung verlagert. Alleine schon die explizite Normierung des Ziels, Infektionen bei der Veranstaltung minimieren zu wollen, halte ich fuer unglaublich wertvoll. Der Text hebt hervor, dass diese Infektionsminimierung nicht alleine eine individuelle Massnahme ist, sondern insbesondere als Gruppenanstrengung umsetzbar ist – es geht nicht vorwiegend um den Schutz der Einzelnen, die sich selber ueberlegen kann, ob sie das will oder nicht, sondern je gemeinschaftlicher das passiert, desto besser werden alle geschuetzt. Es wird klar, dass die Veranstaltung ebenso dazu beitragen wird und stellt dar, welche Unterstuetzung sie dazu leistet (Bereitstellung kostenloser Antigen-Schnelltests und guter FFP-Masken). Einige Mastodon-Diskussionsteilnehmende haben sich sogleich (und immer wieder wiederholt) daran aufgehangen, dass die Kiwipycon das Tragen der Masken zur Pflicht macht – was die Congress-Orga offenbar nicht will. Sie scheinen dabei aber den wichtigeren Punkt zu uebersehen: Allein schon diese Zielnormierung und die Klarstellung, welchen Beitrag der Orga Teilnehmende erwarten koennen, schafft viel mehr Klarheit. Selbst wenn man die zu erwartenden Massnahmen ausdruecklich nicht als Vorschrift sieht, die auch noetigenfalls mit Machtwerkzeug durchgesetzt werden (muessen), spricht solch eine Darstellung eine voellig andere Sprache als „wir halten uns an die Vorschriften, die Vorschriften schreiben nix vor, y’all fight for yourselves“.
Diese Diskussion war sicherlich nicht die letzte, bei der das beschriebene Spannungsfeld sichtbar wird. Ich halte es fuer wichtig, viel haeufiger darauf zu schauen. Allein schon um die immer wieder mitschwingenden Annahmen zu dekonstruieren. Und uns aber auch zu ueberlegen, welche Wertemodelle wir eigentlich mitbringen und an welchen Stellen die clashen. Denn wenn wir als Szene mehr wollen als nur ab und zu bunte Lichter aufzubauen und berauschende Substanzen zu uns zu nehmen, wenn wir wirklich auch gesellschaftliche Visionen ueber diese Schutzraeume hinaus gestalten wollen, muessen wir uns ueber das genaue Ziel zwar nicht einig sein. Wir sollten aber in der Lage sein, zu erkennen, wo Ziele inkompatibel sind – und welche Fragen nach Parrish wir uns bislang noch zu wenig gestellt haben.
Gestern mittag ging fuer mich nach 10 Tagen auf dem Acker das Chaos Communication Camp 2023 vorbei. Am Samstag wollte ich noch gar nicht, dass dieser utopische Eskapismus aufhoert, denn es gibt ja so viel zu sehen, und ich erinnere mich noch, wie traurig ich 2015 und 2019 war, als es vorbei war. Nach zwei Tagen Abbau war ich dann aber doch wieder ganz froh, nicht jeden Abend eine dicke Staubschicht abzuwaschen 😀
Und weil mir irgendwann beim Durchscrollen des Hashtags auf Mastodon auffiel, dass ich quasi nur einen Blogpost zum Camp fand, dachte ich, ich fass mir mal an die eigene Nase und schreib meine Erfahrungen auf. So wie frueher.
Erkenntnis 1: Ich habe das gebraucht. Und wie ich das gebraucht hatte. Die GPN 2022 war ansonsten die einzige Chaosveranstaltung, die ich seit Pandemiebeginn vollständig besucht hatte, und die tat schon gut. Aber als ich an Tag -2 ankam und ueber das Gelaende ging, war das so ein seltsam-nostalgisches Gefuehl, an einen vertrauten Ort zu kommen (ich versuche das Wort „zuhause“ zu vermeiden, obwohl es das erste Wort war, das mir bei der Ankunft in den Sinn kam), dass es mich zeitweise wirklich ueberwaeltigt hat. Ich habe Menschen teilweise zum ersten Mal seit 2019 wiedergetroffen. Es gab so viele Installationen, die Spieltrieb und Schoenheit vereint haben. Und da sind wir noch nicht einmal bei den vielen Gespraechen, Beitraegen und zufaelligen Begegnungen, die zum intensiven Denken anregen, wie wir unsere Welt umgestalten koennen.
Vielen anderen ging das ihren Beschreibungen nach auch so. Eine gewisse Rueckkehr zur Normalitaet. Und gleichzeitig merkte man den ganzen Strukturen, die so ein Camp ueberhaupt erst ermoeglichen, an, dass es seit dem letzten Camp genau einen – vorpandemischen – Congress gab, bei dem die Teams sich einspielen, abstimmen, weiterentwickeln konnten. Vieles hakelte immer wieder, und vor allem bei den spaeteren Veranstaltungstagen funktionierten manche Dinge nicht mehr so gut. Am letzten Abend traf ich eine improvisierte Absperrung bei den Toiletten und jemandem aus einem zentralen Team an, und wir machten eine improvisierte Baendchenkontrollschicht an der Toilette, waehrend ich mir die Lage erklaeren liess. Insbesondere bei den spaeteren Tagen war es offenbar schwer, ueberhaupt noch Engel fuer manche Schichten zu finden. An manchen Stellen sah es zudem so aus, als rumple es bei der Koordination etwas. Die eine Stelle wusste nicht, was die andere machte, manches ging per Stille-Post-Prinzip verloren, und ich muss ehrlich zugeben, ich hatte eine gewisse Faszination bei der Beobachtung, dass es teilweise so aussah, als seien quasi-buerokratische Dienstwege nachgebildet worden, ohne z.B. das Prinzip der Fayolschen Bruecke einbezogen zu haben. Diese Bruecke sei aber anderenorts wieder eingezogen worden, indem sich Engel untereinander quasi-syndikalistisch selber organisiert und Dinge optimiert haetten. Eigentlich ja so, wie man das haben wollen wuerde. Und waehrend wir da sassen, gab es mehrere Versuche, die Absperrung beim Klo wieder zu errichten, weil irgendwerhatgesagt, etc pp.
Das ist gar kein Vorwurf, nur eine Beobachtung. Der sich auch die Beobachtung anschliesst, dass ich mehrmals von Leuten erzaehlt bekam, dass sie dieses Mal einfach nur das Camp erleben wollen wuerden. Was auch bei jeder einzelnen Person voll nachvollziehbar und auch begruendbar war: Die hatten sich ja alle bereits bei vielen solchen Veranstaltungen eingebracht und richtig umfangreich Dinge gewuppt – kann man ihnen nicht uebelnehmen, dass sich dieses Mal ausnahmsweise nicht mehr in dem Umfang einbringen. In der Summe hiess das halt, dass die eingerosteten Ablaeufe jetzt mit dem Wegfall erfahrener Leute kombiniert wurden, und da waren wir nun.
Das Linked Open Data Village, nachts, irgendwann
Ich muss mich da offen gestanden auch an die eigene Nase fassen. Offiziell habe ich auch nur zwei Stunden geengelt und lebenden Leitkegel gespielt – die restliche Zeit ging fuer die Organisation des Village drauf, wo ich aehnliche Effekte mit der Umverteilung der anstehenden Arbeit beobachtete. Ich habe keine Feldkabel gezogen, war nicht Teil des A-Teams, und entgegen meiner grossmaeuligen Ankuendigungen konnte ich auch nicht (viel) im LOC aushelfen, weil das Village zu viel Zeit gefressen hat. Meine grosse Hoffnung ist, dass das jetzt ein einmaliger Effekt nach … *gestikuliert umfassend* … war und sich das zu den folgenden grossen Events wieder einpendelt.
Vielleicht hat das tatsaechlich auch mit der sonst so viel beschworenen Dezentralisierung zu tun. Noch so ne Erkenntnis: Twitter/X ist fuer mich jetzt durch. Das war ein schleichender Prozess seit der Uebernahme durch Elmo. Die Dark-Timeline ist seit Sommer 2022 eh langsam eingeschlafen, die Uebernahme durch den Emerald Idiot hat das beschleunigt, und in den letzten Monaten hatte ich immer weniger Lust auf Twitter. Mastodon fuehlt sich an vielen Stellen immer noch rumpelig an, aber weil Xitter so seltsam wurde, habe ich dort nun spaetestens auf dem Camp aufgehoert, haendisch crosszuposten und ich habe auch den Hashtag dort kaum verfolgt. Andererseits heisst das auch, dass die gemeinsame Infoquelle fuer vieles rund ums Camp nun weggefallen war – die zum Beispiel ueber fehlende Engelschichten informiert haette. Und viele, die ich kenne, haben sich eh wegen *gestikuliert nochmals allumfassend* von Social Media insgesamt verabschiedet, sind nun also auch nicht auf Masto. Dazu kam die Dezentralisierung beim Camp selbst. Keine so richtig zentralen Zirkuszelte mehr fuer das „offizielle“ Programm, viele Villages, die Programm betreiben, Rumpelbuehnen are real. Was aber auch heisst: Wenn zu viel der Energie in die dezentralen Villages laeuft (und die auch die Probleme haben, noch die noetigen Ressourcen aufzubringen), hakt’s bei den zentralen Diensten. Aus Alien-Observer-Perspektive auch wieder spannend.
Abbau. Wehmut. Scheisse viel zu tun.
Letzte Erkenntnis : Ich hatte 2019 gar nicht uebers Camp geschrieben. Derweil wir mal eben nebenbei einen Proof of Concept fuer ein community-basiertes, Freie-Software-basiertes Bikesharing dort ausgerollt und praktisch getestet hatten (hier weiter unten beschrieben) und dort unzaehliges Feedback und vor allem viele direkte Beitraege der vielen neugierigen Menschen einsammeln konnten. Im Nachhinein ziemlich klar: Ich steckte im Sommer 2019 bereits psychisch ziemlich in der Scheisse, ausgeloest durch Ziel- und Wertekonflikte und unmittelbarer Fuehrungskultur beim damaligen Broetchengeber. Wahrhaben wollte ich das damals wohl noch nicht so recht. Zeit, wieder mit diesem Blogging anzufangen. Die Energie vom Camp kommt da nur recht. Und ich ueberlege mir schon einmal, wo und wie ich zu weiteren solchen Veranstaltungen beitragen kann.
Weil, ja, ich habe das gebraucht. Und ich hatte den Eindruck, viele andere auch. Der Vorwurf von 2015 von der angeblichen Gentrifizierung der Hacker*innenszene ist immer noch diskutierenswert. Ich sehe den Ausweg aber nicht darin, sich stattdessen den Strukturen anzubiedern, die derzeit im groesseren System die Macht zu haben. Korrupt schreibt, er habe die Stimmung insgesamt als ein wenig zorniger empfunden. Das kann ein guter Anfang sein.
Hier war das bislang nicht Thema, aber die Ulmer Stadtspitze fuehrt seit spaetestens 2022 etwas, was ich persoenlich nur als einen Beleidigte-Leberwurst-Krieg nennen kann. Gegner sind dabei genau die ehrenamtlichen Aktiven, die seit 2016 den Part bildeten, der das staedtische Foerderprojekt „Stadtlabor“ am Weinhof ueberhaupt erst interessant und sinnstiftend gemacht hatten.
Die ersten Sticheleien der Stadt sind hier und hier dokumentiert, die Aktiven wurden zum Juli 2022 zum Auszug aufgefordert, und im Update vom Herbst 2022 wird glaube ich deutlich, dass entgegen der, ich sage einmal, Geschichtsumschreibungsversuche der Stadt, dieser Auszug keineswegs freiwillig war. Entweder haetten die Aktiven den Namen und die Hoheit darueber, was das Haus ist, abgeben sollen – oder eben gehen.
In der Folge erhob der Vorsitzende der Ulmer CDU-Ratsfraktion in seiner Rolle als Anwalt der Stadt Klage gegen die Ehrenamtlichen, damit diese den Namen aufgeben und der Stadt ueberlassen. Das LG Stuttgart entschied im Fruehjahr 2023 entgegen aller Erwartungen fuer die Stadt, die nun dadurch die Rechte am Namen „Verschwoerhaus“ hat. Die Aussichten auf einen Erfolg in der Berufung standen zwar nicht schlecht. Der Verein der Aktiven konnte aber – auch durch viele solidarische Spenden aus der Szene – gerade so die Kosten fuer die erste Instanz stemmen. So stand am Ende das nur wenig troestliche Ergebnis, zwar moralisch aufrecht gestanden zu haben, aber nicht die notwendigen Mittel gehabt zu haben, um auch rechtlich zu bestehen.
Waehrend nun zwar in Neu-Ulm eine umso mehr zusammengeschweisste Community ein Neues Haus bespielt, hiess dieses Urteil auch, dass eine Reihe von Betriebsmitteln wegfiel, die mit dem von der Community erdachten Namen zusammenhing (und das Gericht bestreitet auch gar nicht, dass der Name aus dem Ehrenamt kam). Ich war vom Sommer 2016 bis zum Urteil ueber eine Mailadresse stefan.kaufmann@verschwoerhaus.de erreichbar – ueber die Domain, die von Anfang an aus der Community registriert und betrieben wurde, und mit der die Ehrenamtlichen nach Meinung des Gerichts nur den Markennamen „Verschwoerhaus“ fuer die Stadt aufbauten (sic!). Das war nun passe.
Zu allem Ueberfluss scheinen sich Stadtspitze und staedtischer Anwalt jedoch nicht mit ihrem Pyrrhussieg zufriedenzugeben, zwar nun den Namen zu halten, aber effektiv nur mehr eine Huelle ohne den ausschlaggebenden Inhalt. Was in dem „offenen Haus“ (das dieses Jahr wegen angeblich dringender Bauarbeiten laenger geschlossen sein wird, als es waehrend der Corona-Hochphasenjahre jeweils aus guten und berechtigten Gruenden war) ueberhaupt fuer die allgemeine Oeffentlichkeit zugaenglich passiert, ist derzeit schwer nachvollziehbar. Die Stadt pflegt zwar eine Website verschwoerhaus.ulm.de, bis zum heutigen 11.8.2023 ist das jedoch nur eine Unterseite der staedtischen Website, die von heute bis Ende des Jahres ganze vier(!) Veranstaltungen fuer die allgemeine Oeffentlichkeit ankuendigt. Auf einer Projektunterseite werden trotz der aktuellen Schliessung weiter vier Oeffnungszeiten pro Woche fuer ein Ukraine-Foerderprojekt und unklarer Zielgruppe angekuendigt. Und was neben diesem Ukraineprojekt passiert ist, scheint enorm uebersichtlich zu sein. Trotzdem versucht die Stadtspitze nun, sich auch der Domain verschwoerhaus.de zu bemaechtigen, um den Ort auch unter der von frueher gewohnten Domain zur staedtischen Veranstaltung zu machen, obwohl der OB 2016 dem Rat versicherte:
dass die Stadt nur anschiebe. Es sei kein kommunales Projekt.
Wohlgemerkt ergibt sich aus dem Urteil soweit ich das erkennen kann kein direkter Anspruch der Stadt. Sie will das halt. Ich weiss nicht, was die Motivation ist – als Baustelle gaebe es ja gerade das Haus selber wieder zu oeffnen, oder mal eine vernuenftige Website zu bauen, oder wenigstens die im Stadt-CMS so zu pflegen, dass man als aussenstehende Person auch weiss, ob die Oeffnungszeiten dort fuer einen sind oder ob sie ueberhaupt stattfinden, etc. – fuer all das braucht es keine Domain, und man muss dafuer auch nicht in Aussicht stellen, Funktionstraeger eines Vereins persoenlich auf sechsstellige Betraege zu verklagen.
Es muss also damit gerechnet werden, dass bei Mails an die gewohnten, seit 2016 ehrenamtlich betriebene Adressen @verschwoerhaus.de irgendwann nicht nur die gemeinten Adressat*innen die Empfaenger*innen sein werden. Sondern dass da irgendwelche Stadtleute unter der Adresse an mich und die anderen so erreichbaren Menschen gerichtete Mails empfangen koennten. Wer mich erreichen moechte, sollte also unbedingt @temporaerhaus.de statt der gewohnten Domain verwenden.
Die ganze Geschichte hatte mich bisher schon rat- und fassungslos gemacht. Auf dem Schulhof gab es einen Namen fuer die Typen, die ihre Macht und Kraft ausgeuebt haben, damit Schwaechere das tun, was sie wollen. Und auch fuer das vor allem in Familien vorgefundene Prinzip „ich bringe das Geld her, also tust du, was ich sage“, gibt es einen Namen. Es ist ein gewisser Trost, dass Menschen, die ich fachlich schaetze, diese Fassungslosigkeit teilen. Das auch vor dem Hintergrund, dass nicht nur bei so laeppischen IT-Standardgeschichten wie dem aktuell halten einer Website fuer mich nicht mehr so arg viel digitale Kompetenz zu erkennen ist. Aber momentan ist davon auszugehen, dass die Stadtspitze und der CDU-Fraktionsvorsteher-und-staedtische-Anwalt die ihnen gegebenen Machtvorteile weiter auf eine Weise einsetzen werden, die mehr als nur ein leichtes Gschmaeckle fuer mich haben. Ich bitte alle Mitlesenden, sich darauf einzustellen. Und den „Ulmer Weg“ der Einbeziehung der Buergerschaft in ihren Digitalisierungsbemuehungen genau zu beobachten, wer hier wem zuarbeiten soll, wer die Machthebel in der Hand hat – und auch, wie sich der „Ulmer Weg“ bei den tatsaechlich vorhandenen Digitalkompetenzen rund um die Leuchtturmprojekte wahrnehmbar ausdrueckt.
Gerade ist (noch) der erste Januar 2023 (und ich stolpere natuerlich immer noch ueber die Jahreszahl). Das heisst, dass ich vor fast exakt einem Jahr um Mitternacht nicht nur ins neue Jahr gefeiert habe, sondern mit einigen anderen Anwesenden High-Fives abgeklatscht habe, weil wir ab dieser Sekunde nicht mehr im oeffentlichen Dienst angestellt waren.
Ich habe aus verschiedenen Gruenden bis heute nie aufgeschrieben, warum ich damals ausgestiegen bin, und auch die anderen Anwesenden haben das nicht an die grosse Glocke gehaengt (ich habe gerade im Kopf durchgezaehlt, und wenn ich das richtig zusammenbekomme, sind 2022 ausser mir sechs andere Menschen aus dem ehemaligen Team gegangen oder nicht zurueckgekehrt, und dieses Jahr weiss ich von zwei weiteren. Das ist schon scary-beeindruckend.)
Eigentlich ist dieses leise-gehen schade. Thilak Mahendran hat am 6.12.2022 seinen Dienstausweis und seinen Arbeitslaptop im Bundesverwaltungsamt abgegeben, wo er das Kompetenzzentrum Open Data leitete. Und im Gegensatz zu mir hat er offen ueber seinen Ausstieg einen Text geschrieben, den ich sehr lesenswert finde. Weil er erstens die Probleme anspricht, die nicht nur im BVA Alltag sind, sondern die eigentlich eigene Tropes im Verwaltungsgame bilden – und absurder-/peinlicherweise auch gerade in den Organisationseinheiten, die die Speerspitze der Digitalisierung und Innovation und hastenichtgesehen sein sollen oder wollen. Und weil er zweitens den ungesunden Feedback-Loop benennt, an dessen Ende nur noch angepasste Ja-SagerInnen uebrig bleiben, die auch an den „fachlich nicht mehr begruendbaren“ Entscheidungen keinen Anstoss nehmen.
Ich beobachte gerade auf Twitter und Mastodon, dass diese Probleme zunehmend auch anderen Leuten aufzufallen scheinen. Dass man Exit-Interviews fuehren sollte, um auch tatsaechlich zu lernen, warum Menschen die Verwaltung verlassen. Wobei ich den Kreis eigentlich weiter drehen wuerde. Eine Erkenntnis aus ueber 10 Jahren datalove/ulmAPI und dem sich daraus entwickelten Verschwoerhaus war, dass es nicht reicht, nur in die Verwaltung wirken zu wollen, um sie zappelnd und schreiend ins 21. Jahrhundert zu bringen. Mindestens so wichtig ist es, in die allgemeine Oeffentlichkeit und die Politik zu wirken. Damit die auch die richtigen Fragen stellen kann. Zum Beispiel, warum denn keine Exit-Interviews gemacht werden. Oder welche Konsequenzen aus Erkenntnissen gezogen wurden. Oder warum Entscheidungen fachlich nicht begruendbar sind.
Das ist aus zwei Gründen bemerkenswert. Erstens wegen des GovTech-Campus selbst, seiner Organisation als eingetragener Verein, in dem Unternehmen für mehrere tausend Euro Mitglied werden können, und der Tatsache, dass dort Ministerien und privatwirtschaftliche Dienstleister unter demselben Dach sitzen und „gemeinsam“ IT-Dienstleistungen entwickeln. Die Lage hebt das als positives Beispiel hervor. Zweitens, weil eher im Nebensatz erwähnt wird, dass es seit vielen Jahren auch eine aktive digitale Zivilgesellschaft in diesem Bereich gibt. Die ehrenamtliche Zivilgesellschaft hat im Konzept des GovTech-Campus aber gar keinen Raum, und wird in der Lage auch nur im Rahmen von Hackathons erwähnt, die an den Bedürfnissen vorbei entwickeln würden.
Derweil kann man argumentieren, dass die Situation, in der die öffentliche Hand bei ihren Digitalisierungsbestrebungen stets auf externe Dienstleister angewiesen ist und mit der Zivilgesellschaft allenfalls im Rahmen von Hackathons interagieren kann, eine Konsequenz des New Public Management ist. In diesem Denkmodell wird die Bevölkerung zu „Kund*innen“ des Staats, der sich – auch in genuinen Aufgaben der Daseinsvorsorge – wie ein Unternehmen verhalten soll. Das heißt zum Beispiel, dass Abteilungen sich untereinander ihre Leistungen in Rechnung stellen. Aber auch, dass Leistungen der öffentlichen Hand an Unternehmen oder eigene Gesellschaften ausgelagert werden. Ein Engagement außerhalb dieser Wirtschaftslogik ist gar nicht vorgesehen – das heißt, die umfangreiche praktische Digitalisierungsexpertise aus dem Ehrenamt zerschellt regelmäßig an der staatlichen Organisationspraxis.
Schon für die Anforderungsbeschreibung von Digitalprojekten braucht es externe Beratung
Wünschewand beim OpenCityCamp 2012
Das hatte gerade für die Digitalisierung fatale Folgen. Anstatt IT-Architekturkompetenzen auf allen Ebenen der föderalen Verwaltung aufzubauen, bestimmt seit Jahren eine Reihe externer Dienstleister, wohin der Staat digitalisiert. Was auf den ersten Blick wie eine Effizienzsteigerung klingt – denn natürlich sollen nicht über 11000 Kommunen jeweils ihre eigene Softwarelösungen entwickeln – führte über die Jahre zu einem weitreichenden Kompetenzverlust schon bei der Bestimmung, was eigentlich die Anforderung an die zu bauenden Softwarearchitekturen sind. Als Nebeneffekt kann es dann auch schon einmal vorkommen, dass die beschaffte Software am Ende gar nicht für den gedachten Einsatzzweck taugt und das Projekt für die Katz war. Lilith Wittmann nennt das in ihrer kritischen Besprechung des GovTech-Campus die „Beratertreppe“: Die laufende Externalisierung von Kompetenzen wurde zur selbstverstärkenden Spirale, so dass seit Langem schon für die Erstellung der Ausschreibungen für ein Softwareprodukt externe Beratung herangezogen werden muss.
Diese Erfahrung haben in den vergangenen Jahrzehnten auch immer wieder Ehrenamtliche aus der Zivilgesellschaft gemacht. Analog zur Civic-Tech-Bewegung in den Vereinigten Staaten entstanden in den späten 2000er-Jahren auch in Deutschland Gruppen Freiwilliger, die am praktischen Beispiel aufzeigten, was mit den Mitteln der Informationstechnik eigentlich möglich wäre. Als Instrument der Selbstermächtigung und zivilgesellschaftlichem Gegenstück zu Open Government entstanden Transparenz fördernde Auswertungen offener Daten, aber auch ausgereifte Beispiele, wie die öffentliche Hand ihre Leistungen für die Bevölkerung noch besser benutzbar machen kann.
All diese Gruppen stießen jedoch früher oder später auf die immer selben strukturellen Hürden, wenn es darum ging, dass der Staat ihre Ideen auch aufgreift und sich zu eigen macht. In ihrem Buch „A civic technologist’s practice guide“ beschreibt die ehemalige leitende 18F-Mitarbeiterin Cyd Harell zwei notwendige Schritte für die erfolgreiche Anwendung von Civic Tech: „Showing what’s possible, and doing what’s necessary“. Dieser Pfad, dass Ehrenamtliche aus der Zivilgesellschaft zeigen, was möglich wäre, und der Staat dann das Notwendige tut, um sich diese Beispiele zu eigen zu machen, scheint in Deutschland aber fast nirgendwo vorgesehen zu sein. Meist ist man entweder zivilgesellschaftliche „Kund*in“ des Staats und kann allenfalls im Rahmen von Anhörungen und Feedbackrunden Jahr für Jahr dieselben Post-Its auf Metaplanwände kleben – oder man muss selbst Dienstleister*in werden und sich beauftragen lassen, der eigenen Idee irgendwo im Wildwuchs der Verwaltungs-IT ein Gärtchen bestellen zu dürfen.
Für gestaltende Zivilgesellschaft ohne wirtschaftliches Interesse gibt es in diesem Denkmodell keinen Raum
kleineAnfragen.de: 2014–2020
Für die Unterstützung der Umsetzer-Rollen gab es über die Jahre verschiedene Ansätze: Inkubatorprogramme, Förderlinien, Kooperationen mit Umsetzungspartnern aus der Wirtschaft. Das waren aber allesamt lediglich unterschiedliche Geschmacksrichtungen entweder von Firmengründungen oder kurz- bis mittelfristigen finanziellen Förderungen, damit Weiterentwicklung und vor allem Wartung und langfristiger Betrieb wenigstens nicht in der Freizeit der Beteiligten passieren musste. Wir haben im Ergebnis bis heute keinen Ansatz, um langfristig einen Pfad zu ebnen, dass die öffentliche Hand selbst fertige, von der öffentlichen Hand direkt übernehmbare Produkte wie kleineanfragen.de auch selber betreiben könnte, und sei es über Konstrukte wie die kommunalen Rechenzentrumsverbünde. An die Stelle von Civic Tech aus einer engagierten Bürgerschaft und einer Verwaltung, die selbst in der Lage ist, aus deren Erfahrungen zu lernen, ist GovTech getreten – also die vollständige Abhängigkeit von Firmen, die teils den Staat als einzigen Kunden für ihre Produkte haben.
Das ist auch eine Erfahrung der Zivilgesellschaft aus jahrelanger Beschäftigung im Austausch mit der Verwaltung – sei es bei selbst organisierten Barcamps oder der Beteiligung an Hackathon-Formaten. Und hier zeigt sich eine weitere problematische Konsequenz dieser Kompetenzauslagerung durch den Staat. Eher im Nebensatz erwähnt Philip Banse, dass es neben dem ebenfalls auf dem GovTech-Campus vertretenen Digital Service des Bunds auch Ehrenamtsnetzwerke wie Code for Germany gebe – aber die würden ja eher Hackathons machen und an den Bedarfen der öffentlichen Hand vorbei entwickeln.
Aus Sprints werden Marathons – aber warum sollen Ehrenamtliche laufen, und nicht der Staat?
Indes waren es gerade die Ehrenamtlichen des Code-for-Germany-Netzwerk, die auf den Nachhall des großen Corona-Hackathons der Bundesregierung 2020 in Form einer Wiederentdeckung von Hackathons durch die öffentliche Hand und seinen Partnerorganisationen wie Tech4Germany (aus dem der oben erwähnte Digital Service hervorging) eher verhalten reagierten. Viele der Code-for-Germany-Aktiven haben über die Jahre hinweg Begegnungen mit Hackathonformaten gehabt – und merkten über die Zeit, dass sie zwar an Erfahrung dazulernten, wie die Verwaltung funktioniert, aber immer wieder auf dieselben Probleme und Hilflosigkeiten dieser Verwaltung stießen, die schon auf den Austauschformaten mehrere Jahre zuvor adressiert werden sollen hätten. Die Erfahrung der Code-for-Germany-Ehrenamtlichen zeige, „dass es weniger um die Prototypen als viel mehr [um] Erkenntnisse auf einer strukturellen Ebene“ gehe, heißt es in einer Handreichung des Netzwerks vom Sommer 2020.
Zum einen geht es bei Hackathons wegen des immer noch vielfach genutzten Wettbewerbscharakters nämlich viel zu häufig um den Start neuer Projekte. Häufig werden also Ideen neu erfunden, an denen andere Gruppen bereits – beispielsweise aus eigener Betroffenheit – zur Verbesserung einer konkreten Situation gearbeitet haben und nun Unterstützung zur Weiterentwicklung und Wartung gebrauchen könnten. Zum anderen laufen auch die „Verstetigungsprogramme“ bis heute meist auf die finanzielle Unterstützung der Ideengeber*innen oder die Entwicklung der Ideen in ein Geschäftsmodell hinaus. Aus dem Sprint werde ein Marathon, hieß es im Nachgang des Corona-Hackathons – ohne dabei die Frage zu stellen, warum denn nun ausgerechnet die Zivilgesellschaft einen Marathon laufen soll, und nicht der Staat.
Die ausgearbeiteten Lösungen aus dem Digitalen Ehrenamt liegen meist schon vor – haben aber selten Chance, zu verfangen
So stellte eine Kommune die Herausforderung vor, die Beschlüsse des Gemeinderats „erlebbarer, einfacher auffindbar und transparenter“ zu machen. Das Ratsinformationssystem der Kommune habe in der Regel Schnittstellen, um diese Informationen abrufen und beispielsweise auf einer Karte darstellen zu können. Bei der beschriebenen Schnittstelle handelt es sich um den seit 2012 durch Ehrenamtliche bei Code for Germany entwickelten Standard OParl. Und die Ironie der Challenge ist, dass, wie gerade erst von Nora Titz beschrieben, am Anfang dieser Standardisierung genau solche grafischen Aufbereitungen der Ratsinformationen standen – damals mit Scrapern aus den Informationssystemen extrahiert und beispielsweise auf Karten dargestellt. Die für die Öffentlichkeit nutzbaren, im Ehrenamt entwickelten Frontends für die Auswertung der OParl-Daten konnten bis heute nicht von der öffentlichen Hand übernommen, geschweige denn betrieben werden. Teilweise scheint es ihr schon schwerzufallen, die beim Ratsinformationssystem-Anbieter bestellte OParl-Schnittstelle auch auf ihre korrekte Installation zu überprüfen und abzunehmen. Die OParl-Schnittstelle der Challenge-gebenden Stadt war zum Zeitpunkt des Hackathons gar nicht aktiviert – und ist es auch zum Zeitpunkt dieses Artikels noch nicht. Es existiert zwar ein fertiges Validierungsskript, mit dessen Hilfe man die Standardkonformität der Schnittstelle in Minutenschnelle prüfen kann. Um dieses Skript bei der Abnahme im Verwaltungsnetz ausführen zu können, bedarf es aber der internen Fähigkeiten, den Validator auf Verwaltungsrechnern selbst zum Laufen zu bringen. Danach braucht es noch etwas Verständnis, die Ausgaben interpretieren zu können und sich vom Dienstleister nicht einreden zu lassen, dass der Fehler bei einem selber liege. Was engagierten Freiwilligen mit grundlegenden Kenntnissen eine spielerische Fingerübung weniger Minuten ist, stellt die Verwaltung teilweise heute noch vor große Herausforderungen. Der Staat baut hier nicht die notwendigen Kompetenzen in der Breite auf, um die gratis vom Ehrenamt gelieferten Skripte auch selbstbestimmt ausführen zu können. Stattdessen sind diese Ehrenamtlichen letztlich dazu gezwungen, selbst als bezahlte Dienstleister*innen aufzutreten, wenn sie wollen, dass ihre Ideen auch in die Tat umgesetzt werden.
Vorhandenes Wissen aufgreifen und dokumentieren – nach den Bedürfnissen des Ehrenamts!
Die überstarke Begeisterung des Staats für Hackathons scheint mittlerweile – zum Glück! – endlich abzuflauen. Offen bleibt aber die Frage, wie Ehrenamt und Zivilgesellschaft sich überhaupt wirkungsvoll mit ihrer Expertise einbringen können. Der Anspruch kann dabei nicht sein, auch als Zivilgesellschaft ein Büro am GovTech-Campus zu haben. Schon die Existenz eines GovTech-Marktes ist mehr Indikator eines grundsätzlichen Problems, als dass diesem Markt mit einem Austauschcampus noch niederschwelligerer Zugang geschaffen werden soll. Es kann auch nicht die Aufgabe Ehrenamtlicher sein, werktags mit am Tisch zu sitzen, wenn Vergabeverfahren für staatliche IT-Lösungen nun möglicherweise noch weniger nachvollziehbarer als bisher zwischen Verwaltung und Dienstleistern ausgehandelt werden. Vielmehr geht es darum, den Wissensschatz der ehrenamtlichen Digitalen Zivilgesellschaft aktiv zu suchen und in die Verwaltung selbst zu transferieren.
Wikimedia Deutschland hat gemeinsam ergänzt um Interviews mit der Deutschen Stiftung für Ehrenamt und Engagement vergangene Woche im Politikbrief „Digitales Ehrenamt: Zivilgesellschaftliche Teilhabe im Digitalen Raum“ sechs Forderungen aufgestellt, wie dieses Engagement besser vom Staat gewürdigt und gefördert werden sollte. Eine der Forderungen ist der systematische Transfer ehrenamtlicher Expertise. Der Staat sollte nicht etwa Dienstleister*innen auf seinen GovTech-Campus zu sich einladen und damit weiter Kompetenzen externalisieren, sondern strategisch interne IT-Fähigkeiten aufbauen. Das vorhandene Wissen im digitalen Ehrenamt muss durch aufsuchende Beteiligung und den Bedürfnissen der Freiwilligen folgend aufgegriffen und dokumentiert werden, um es verwaltungsintern verwendbar und anwendbar zu machen. Damit könnte endlich eine Brücke über die nach wie vor bestehenden Wissensklüfte geschlagen werden – damit kommende Generationen ehrenamtlich Aktiver hoffentlich künftig nicht mehr zu ihrer Frustration auf dieselben strukturellen Hürden stoßen, an denen diese Partizipation bislang scheiterte.
//edit am 24. Januar 2023, Rolle der DSEE im Politikbrief von WMDE korrigiert