Ab 09:27 kommt im Video ein anschauliches Beispiel des dahinter liegenden Paradigmenwechsels. Anstelle von Apps, die auf hardcodierte APIs zugreifen muessen (und die dann wieder angeflanscht an zentralisierte Datensilos sind), werden Abfragen im dezentralen Modell lokal synthetisiert. Die notwendigen Daten kommen dann aus denjenigen verteilten Quellen, die fuer genau diese Frage notwendig sind.
In Ergaenzung (und technisch notwenige Voraussetzung) zum auf den Kopf gestellten Nutzungsversprechen von Open Data erlaubt diese Herangehensweise eine Abkehr von zentralisierten Superdatenplattformen. Die bisherige Idee war, dass es ja eine Vielzahl von Fachverfahren gebe, deren Daten in einzelnen Silos liegen. Um das aufzubrechen muessten Verfahren standardisiert werden und alle Daten in ein zentrales Silo anliefern. Was auch bedeutet, dass z.B. einzelne Kommunen oder Bezirke ihre bisherigen Fachverfahren fuer ein Thema aufgeben und sich der Mehrheit anschliessen muesten – und sei es mit Zwang. Im Gegenmodell waere die interne Datenhaltung oder zumindest das Ergebnis eines ETL-Prozesses der Fachverfahrensdaten ein Knowledge Graph – und ueber verteilte Knowledge Graphs lassen sich wie im Video demonstriert wunderbar Abfragen fahren, nur durch die Magie von 5-Sterne-Daten mit Semantik. Die Bausteine dafuer sind mittlerweile Jahrzehnte alt und gut abgehangen. Und eigentlich passt das auch viel besser in das Modell eines foederalen Staats, der nicht alles von oben her vereinheitlicht und nach oben hin an sich zieht, sondern auf den Ebenen auch Entscheidungsspielraeume laesst.
Lilith Wittmann ist wie immer gleich deutlich radikaler und sagt: Alles bis drei Sterne sollte eigentlich gar nicht mehr zaehlen, wir muessten noch weiter gehen und Open Data erst ab vier Sternen ueberhaupt „zaehlen“ lassen:
Das Problem ist aber: Wir haben seit 15 Jahren dieselbe Vision, bei der alles ab Schritt 4 in weiter Ferne erscheint. Und gerade in Deutschland kam nie irgendwas über 3⋆ hinaus.
Deshalb schlage ich heute eine neue Version von 5⋆ #OpenData vor.
Ich bin gerade noch einmal ueber den Vortrag „CKAN: apt-get for the Debian of Data“ vom 26C3 im Dezember 2009 gestolpert. Rufus Pollock (Gründer von Open Knowledge International) und Daniel Dietrich (Mitgruender des deutschen Ablegers, der OKFde) erklaerten damals ihre Vision eines Netzwerks von Datenquellen.
Das heute, knapp 12 Jahre spaeter noch einmal anzusehen, war… spannend. Ich zucke heute ueber das “this is when nerds run things” am Anfang peinlich beruehrt zusammen, aber es lohnt sich total, noch einmal aufzurollen, was in der Zwischenzeit alles (nicht) passiert ist:
Der gesamte Vortrag denkt in (vermeintlich) notwendigen Lizenzen fuer Daten – “Free Data“ von Denny Vrandečić wird erst drei Jahre spaeter veroeffentlicht werden. An ganz vielen Stellen betont Pollock, dass es total wichtig sei, irgendeine Lizenz anzugeben – das haelt sich leider an vielen Stellen bis heute und klebt uns als Bewegung am Bein.
Ueberhaupt, die ganze Idee von CKAN: Versionierung, Packages etc., wo sind wir 12 Jahre spaeter? Man denke nur an die RKI-Daten waehrend der Covid-Pandemie. Oder auch die gesamte Idee mit Dependencies und weiteren herunterzuladenden Datenpaketen. Die schmeckt ein wenig wie Linked Open Data – und ich haette das sehr gerne in der Praxis. Habe ich aber noch nie gesehen. (Bei 53:20 ff. wird das am Beispiel der Postleitzahlen beschrieben)
„Schaut mal, die Briten nehmen schon CKAN um Open Data zu veroeffentlichen und wir hoffen, dass das die deutsche Politik ueberzeugt, ebenfalls Open Data herauszugeben“. Ohweh, das tut weh.
Generell, die ganze Begeisterung – Daten werden wichtiger als Code werden, mit Gibson-Zitaten, etc.pp. – das haengt sicher auch mit meiner romantischen Vergangenheitsverklaerung zusammen, aber da kommt schon ein wenig Nostalgie auf 😉
Ab 44:36 kommt eine hervorragende Frage: Jetzt taucht da ein Katalog mit Daten auf – ist das langfristig nicht sowas wie es Webkataloge vor Websuchmaschinen waren? Sollte das nicht alles von Maschinen erfassbar und bearbeitbar sein anstatt haendisch? Pollock erklaert ein bisschen herum, aber in dem Austausch ist IMO ein Kernproblem der ganzen Datenportale bis heute sehr klar vorhergesehen.
Vor allem auch: Wer vertritt all diese Visionen heute ueberhaupt noch, um eher industriegetriebenen Memes wie dem „Datenraum“ etwas entgegenzuhalten? Wo bleibt das Zukunftsversprechen von Linked Open Data, so dass ich morgens nur einen Update-Befehl ausfuehren muss, um das (versionierte, aktuelle) Paket z.B. fuer die Impfdaten des RKI zu bekommen?
Tatsaechlich gibt es mittlerweile schon einige Ansaetze, wie auch die vielen ehrenamtlichen Gruppen gefoerdert werden koennen, und nicht nur die Fraunhofers und sonstigen etwas verstaubten grossen Player. Der Prototype Fund der OKF DE ist ein Beispiel, und dass die Stadt Ulm der Civic-Tech-Community ein ganzes Haus samt Ausstattung zur Verfuegung stellt, findet hoffentlich bald Nachahmung in anderen Staedten.
Eine Sache fehlt aber nach wie vor ganz gewaltig, und das ist Beratung. Auch als Bruecke, um die vielen Ideen, die in den OK Labs und anderen Initiativen entstehen, ueberhaupt erst in einen Zustand zu versetzen, um sich beispielsweise fuer den Prototype Fund bewerben zu koennen.
Startup- vs. Gemeinwohlberatung
Es ist ja eigentlich eine Crux: Wer heutzutage ein Startup gruenden und VC-Gelder verbrennen moechte, findet an jeder Ecke institutionalisierte Beratung. Gruenderzentren, IHK und Co. pruegeln sich geradezu, wer denn nun kompetenter beraten kann, Literatur gibts zuhauf, und wenn die politischen Signale guenstig stehen, fliessen auch die Foerdertoepfe grosszuegig.
Fuer Civic-Tech-Projekte – insbesondere diejenigen, aus denen sich kein Geschaeftsmodell entwickeln laesst, sondern deren Gemeinnuetzigkeit dem entgegensteht – sieht die Lage mau aus. Das klang neulich schon an, als ich nach Alternativen zu den von unbedachten Hackathon-Veranstaltern oft ausgelobten grossen Barpreisen fragte:
längerfristige Förderung & Unterstützung von den enstandenen Projekten
Was auffaellt: Viele der Vorschlaege drehen sich um Mentorierung und Folgefinanzierung – der Rest um die schon im Dezember angesprochenen Huerdensenker wie Reisekosten etc.
Weil
Wiederkehrender Dialog: „Ja ey, [XYZ] bräuchte es!“ „Ja, und man könnte den Service sogar als Geschaeftsmodell bauen“ „Hm“ „Kein Bock“ „Jo“
Jedes Mal in einer Runde mit faehigen Leuten[1], die die Idee garantiert umsetzen koennten. Und fuer die der Schritt aber gefuehlt zu gewagt ist, ihre (in der Regel) Festanstellung zu reduzieren und nebenher finanziert aus $Foerdertopf dieses Projekt voranzubringen. Oder es laeuft noch viel banaler, und die oertliche Civic-Tech-Gruppe bekommt von Lokalpolitikern eingefluestert, dass man sie schon laengst in einem Foerderprogramm untergebracht haette, wenn sie nur endlich mal einen gemeinnuetzigen Verein gegruendet haetten.
Diese Kluft haette ich gerne ueberbrueckt. Damit nicht nur Vereinsprofis und die jetzt schon freiberuflich arbeitenden Softwareentwickler*innen eine Chance auf Foerderung haben, sondern auch moeglichst viele andere.
Auf dass es bald in jedem OK Lab heissen kann:
Wiederkehrender Dialog:
„Ja ey, [XYZ] bräuchte es!“
„Ja, und das wuerde sogar zu [Foerdertopf] passen“
„Hm“
„Ich frag mal die Civic-Tech-Sprechstunde“
„Jo“
[1] Meine Definition in diesem Kontext: Leute, die etwa tausendfach besser Software entwickeln koennen als ich. Das fuehrt unweigerlich dazu, dass ich von enorm vielen faehigen Leuten umgeben bin.
Drei (plus x) Lese- und Ansehempfehlungen, die mir gestern nach und nach in den Twitterfeed gepurzelt sind und ebenfalls zur Frage passen, wie Civic Tech weitergesponnen werden kann.
It’s just that, we don’t really know what that means. Or, at least, not yet.
So far, every “Smart City” pilot project that we’ve undertaken here in Boston has ended with a glossy presentation, and a collective shrug. Nobody’s really known what to do next, or how the technology and data might lead to new or improved services.
Es folgt ein Rant ueber Vertriebsdrohnen von „Smart City“-Verkaufsbueros, eine Rueckbesinnung auf die Menschen, um die’s gehen soll, dass es nicht noch eine Plattform braucht (!!! zefix!!!), und dass im Zweifel eine „Clevere“ Stadt besser ist als eine „Smarte“: Mit einem Prototypen, einer intelligenten Strassenlaterne. Kleinen Spielplaetzen, die spaeter vielleicht hochskaliert werden, wenn sie sich bewaehren. Anstelle von Alles-oder-nichts-Megaprojekten.
Um Ausschluesse geht es – drittens – auch in Programming is Forgetting: Towards a New Hacker Ethic. Der etwas mehr als 20minuetige Vortrag (siehe oben) ist hier komplett transkribiert und lohnt sich zu lesen, gerne auch haeppchenweise. Am Beispiel einer Anekdote um die juengst mit der Presidential Medal of Freedom ausgezeichneten Margaret Hamilton zerlegt Allison Parrish Stueck fuer Stueck die „Hackerethik“, wie sie Steven Levy 1984 in seinem Buch “Hackers” dargestellt hatte. Nach einem Exkurs ueber soziale Kontexte stellt sie den urspruenglichen Lemmas jeweils eine Frage gegenueber. Und ich finde sie grossartig:
(danke @lorz und @mjays fuer die Links. Ich weiss leider nicht mehr, von wem ich den Vortrag retweeted bekam.)
Foto: Sebastián Laraia für Deutsche Bahn / CCBY4.0
Mittlerweile hat sich herumgesprochen, dass Hackathons eine ganz gute Moeglichkeit sind, die eigene Stadt, Behoerde oder Konzern zu oeffnen und sich frischen Wind in die verstaubten Hallen zu holen. Das BMVI lud derletzt zum zweiten Mal zum Data Run, und die Deutsche Bahn hatte gestern den fuenften Hackathon binnen 20 Monaten ueber die Buehne gebracht. Nicht schlecht, koennte man sagen.
Was mir aber schon bei unseren OpenCityCamps auffiel: Nach einer Weile scheint sich das etwas totzulaufen. Die ausrichtende Einrichtung darf von Mal zu Mal neue Datenquellen freischaufeln, um sich nicht dem Vorwurf auszusetzen, es bewege sich nichts mehr. Ob diese – muehsam irgendeiner grantelnden Fachabteilung abgetrotzten – Daten dann helfen, tatsaechliche Probleme echter Menschen zu beheben, weiss vorher kein Mensch. Und irgendwann ist auch der Punkt erreicht, an dem die naechsten grossen zu beackernden Baustellen einfach gar nicht mehr an einem 24-Stunden-Hackathon bearbeitet werden koennen.
Vor diesem Hintergrund deswegen mal ein paar halbgare Einwuerfe, was mir die letzten eineinhalb Jahre so durch den Kopf gegangen ist:
Mit das wichtigste Ergebnis einer Open-Data-Veranstaltung ist, dass sich die Teilnehmer*innen live treffen und austauschen. Egal ob Freiwillige mit Ministeriumsleuten, Ministeriumsleute mit Konzernbeschaeftigten oder sonstwas: Diese Aufeinandertreffen motivieren, inspirieren und sorgen fuer die notwendige regelmaessige Hirnbelueftung mit frischen Ideen. Fuer diesen Austausch muss genuegend Zeit und Raum vorhanden sein. Das haben wir als blutjunge Fachschaftler*innen bei der Konferenzorga zwar gelernt, bei Behoerden darf man von dem Wissen aber nicht unbedingt ausgehen 😉
Hierzu gehoert auch: Wenn ein Ministerium, eine Landeseinrichtung, ein Staedtetag oder sonstwer eine schicke Austauschveranstaltung macht, dann sollte sie unbedingt auch die Freiwilligen aus der Community mit einladen. Die OPEN! hat das nach der Kritik von 2015 dieses Jahr gemacht, das VDV-Verkehrscamp ebenso. Weiter so!
Irgendwann ist jedoch der Punkt erreicht, an dem das klassische Hackathon-Wettbewerbs-Format nicht mehr traegt. Erstens, weil beim Coden immer die Frage im Raum steht, mit welchem Projekt man denn Preise gewinnen kann. Anstelle der Frage, was nuetzlich, wichtig und sinnvoll waere. Zweitens, weil es das Potenzial verschenkt, gemeinsam mit den vielen tollen, kompetenten Leuten mal ein Wochenende lang strategisch wichtige Dinge auszuarbeiten. Mal dieses Werkzeug uebersetzen. Oder dieses Tool schreiben, das es noch nicht gibt und das bisher jedes Mal irgendwie fehlte. Gruppenuebergreifende Metaprojekte, bei denen jede Gruppe einen kleinen Teil fuer das Gesamtprojekt entwickelt
Aus 1) und 2) folgend: Der konsequente naechste Schritt waere, genau solche Zusammenkuenfte zu foerdern. Bei denen nicht kompetitiv Prototypen gebastelt, sondern gemeinsam die Dinge beackert werden, die fuer die Weiterentwicklung von Open Data in Deutschland wichtig sind.
Die Teilnahme an den Aktionen in 3) darf nicht mehr nur auf den Schultern von Leuten mit viel Zeit oder ausreichend Geld oder beidem ruhen. Die Freiwilligen, die sich ein Wochenende um die Ohren schlagen, duerfen nicht auch noch aus eigener Tasche Anreise und Unterkunft bezahlen muessen, oder per Anhalter anreisen und dann irgendwo auf WG-Sofas pennen. Wer quer durch Deutschland zu so einer Aktion reist, gibt fuer solch ein Wochenende je nach Zeit-Geld-Tradeoff irgendwas zwischen 30 und 300 EUR aus. Das kann sich nur eine ueberschaubare Gruppe privilegierter Leute leisten.
An jeder Ecke wird derzeit haufenweise Kohle auf Big Data, Blockchain 4.0 in der Cloud as a Service und andere Ideen mit ueberschaubarer Halbwertzeit geworfen, die aus irgendeinem Berater-Powerpoint gefallen sind. Foerderfunds werden ins Leben gerufen, auf die sich aufgrund der Rahmenbedingungen letztlich eh nur die ueblichen Verdaechtigen bewerben und die Kohle in bekannter Manier zum Fenster rauswerfen.
Ich wage zu behaupten: Die Foerderung von Veranstaltungen wie in 3) beschrieben und die Vergabe von Reisestipendien fuer Open-Data-Aktivist*innen haette ein deutlich besseres Preis-Leistungs-Verhaeltnis. Da wuerde auch wirklich ein Bruchteilder 100 Millionen des BMVI reichen.
Es gibt ja so Veranstaltungen, nach denen geht man voller Motivation nach Hause. Bei mir sind es gerade fuenf Open-Data-Veranstaltungen in fuenf verschiedenen Staedten an den letzten vier Wochenenden gewesen, und sollte jetzt noch irgendwas kommen fallen mir vermutlich vor lauter Grinsen die Ohren ab.
Aber der Reihe nach.
Berlin: Bahn, die erste
Beste Aussichten hatte am ersten Märzwochenende der Workshop, den die OKF fuer die DB Station&Service in Berlin ausrichtete – buchstaeblich wie metaphorisch. Die Station&Service moechte naemlich sich und ihre Daten oeffnen, wie das die SNCF in Frankreich bereits getan hatte. Die Personenzusammensetzung war genau richtig, und ich am Ende ganz schoen geschlaucht vom Brainstormen und reden. Ich bin sehr gespannt, wie es hier weitergeht, und hatte mir den gesamten Abend danach und die Heimfahrt noch ueberlegt, welche Community-Teile zum Beispiel aus der OpenStreetMap sich hier noch verknuepfen lassen.
Freiburg: Hackathon unterm Sternenbanner
Ganz ohne Getoese hat sich auch Freiburg einen festen Platz auf der Landkarte der innovationsbereiten Staedte verschafft. Das liegt auch an Ivan Acimovic, der in seiner Stadtverwaltung auf ueberraschend viele Open-Data-Vorantreiber_innen bauen kann – und gleich mit einer halben Armee von Mitstreiter_innen einen Open-Data-Hackathon im Carl-Schurz-Haus aus dem Boden stampfte.
Mit der Stadt alleine war es naemlich nicht getan – bwcon Suedwest, das Carl-Schurz-Haus und Profs der Hochschulen Offenburg und Furtwangen warfen sich mit ins Zeug, um diese Veranstaltung durchzufuehren. Dass alle Ergebnisse im Rathaus ausgestellt werden, ist da nur konsequent.
Neben den zu erwartenden Wiederkehrern auf allen Open-Data-Hackathons (natuerlich gab es eine neu erfundene Issue-Tracking-App, die nicht bestehende Loesungen wie Mark-A-Spot verwendet :D) stach fuer mich „Frieda“ besonders hervor: Eine benutzerfreundlichere Neuinterpretation des Freiburger Datenportals FR.ITZ, das bei der Usability noch… Potenzial hat.
Ein wenig schade, dass dieses Projekt bei der Preisvergabe nicht mehr gewuerdigt wurde – zusammen mit dem Projekt „Data Canvas“, das Datenangebot und Bedarfe anhand von Problemstellungen analysieren wollte, haette ich „Frieda“ deutlich hoeher gerankt. Ich bin gespannt, wie viele der Projekte noch weiter entwickelt werden – und wie viele der enthusiastischen Teilnehmer_innen beim kommenden OK Lab Freiburg zu sehen sein werden, das ich leider ganz alleine vertreten musste 🙂
Frankfurt: Die Bahn bewegt (sich) doch!
Und eine Woche spaeter verstummten die Voegel, und der Mond verdunkelte die Sonne, und das scheinbar undenkbare geschah: Die Deutsche Bahn lud zu einem Datenhackathon!
Gerade mal zwei Wochen vorher hatte ich ueberhaupt davon erfahren – ironischerweise auf dem Rueckweg vom DB-Workshop in Berlin, auf dem wir uns fragten, wann sich denn die DB Fernverkehr endlich bewegen wuerde. Der Hackathon war wohl binnen weniger Wochen auf die Beine gestellt worden und war fuer mich eine ausgezeichnete Gelegenheit, einmal mit den Leuten im Konzern zu sprechen, die gerne viel mehr Daten freigeben wuerden – die aber nicht einfach machen duerfen, wie sie gerne wuerden.
In gigantischer 1970er-Jahre-James-Bond–Superschurken-Hauptquartier-Atmosphaere hackten immerhin rund 50 Teilnehmer_innen an den noch-nicht-wirklich-offenen Daten der Bahn – Daten, an die in einigen Faellen wohl bislang selbst die Bahn-Leute konzernintern noch nie herangekommen waren, und die es nur durch diesen Hackathon erstmals aus ihrem jeweiligen Silo herausgeschafft haben. Ausgangszustand: Dass die Teilnehmer_innen „nur“ ein einseitiges NDA-Dokument unterzeichnen mussten, ist bereits ein grosser Fortschritt.
Ich warte jetzt jedenfalls ganz gespannt, dass die Ergebnisse des Hackathons konzernintern durch die Entscheiderpositionen sickern – und hoffe instaendig, dass wir demnaechst einmal ein Transit-Camp auf die Beine stellen koennen, bei dem Vortraege, Austausch und Coding Hand in Hand gehen. Idealerweise mit einem Augenmerk auf moeglichst hohe Diversitaet – Fahrtkostenbezuschussungen und eine inklusivere Ansprache koennten viel dazu beitragen, nicht nur die ueblichen Verdaechtigen bzw. die Leute aus dem direkten Umland anzulocken 😉
Schade, dass das Geschlechterverhältnis beim #DBHackathon so sehr unausgeglichen ist. @DB_Bahn, wollt Ihr dagegen in Zukunft etwas machen?
Solcherlei Inklusivitaetsfoerderung war fuer Moers dagegen gar kein Problem – Dank Reisekostenbezuschussung waren „die Ulmer_innen“ gleich zu zweit beim dortigen Hackday, und auch aus Berlin kamen Abordnungen an den Niederrhein.
Claus Arndt tut sich schon seit einiger Zeit damit hervor, am Rande der Einoede zwischen Pott und den Niederlanden in seiner Kommune das Thema voranzubringen — und kann in seiner Position hierzu auch einiges bewegen. Zum Beispiel diesen Hackday zu veranstalten, bei dem sich auch gleich Interessierte aus dem gesamten Umland fanden, um auch gleich ueber eine Gruendung von „Code for Niederrhein“ nachzudenken.
Moers zeigt fuer mich vor allem, dass Erfolg bei Open Data momentan weniger das Ergebnis grossangelegter Strategiepapiere ist, sondern vom Aufeinandertreffen einer aktiven Community auf engagierte Einzelpersonen mit Gestaltungsspielraum in der Verwaltung lebt. Die besten Absichtserklaerungen, die tollsten Forschungsprojekte nuetzen nichts, wenn die Verwaltung nicht dafuer sorgen kann, dass die freiwilligen Datenveredler ihren Spass nicht verlieren. Indem sie zum Beispiel die Rahmenbedingungen schafft, dass 1.) Daten reibungsarm beschafft werden und 2.) Ergebnisse reibungsarm den Weg zurueck in die Verwaltung finden koennen. In Moers klappt das.
Im Video klingt es auch ein wenig an: Neben Redeployment-Auslotung hatten Juka und ich auch inhaltlich was gemacht, Verkehrszaehlungsdatenauswertung naemlich. Dazu kommt aber noch spaeter mehr 🙂
Leipzig: Code for Germany meets again
Etwas ueber ein Jahr nach dem Auftakt von Code for Germany waren Rens und ich zum gemeinsamen Workshop in Leipzig — um eine grossartig gewachsene Familie von OK Labs zu treffen, die sich mittlerweile auf verschiedenste Themengebiete verteilt hat, von Spielplatzkarten bis zu Feinstaubsensoren fuer jede_n zum Selbst-aufstellen.
Dementsprechend werden mittlerweile auch die Herausforderungen umfangreicher. Ging es anfangs um die Vernetzung an sich, Sichtbarkeit und Austausch, geraten wir als Gemeinschaft nun an die etwas knackigeren Probleme — offenbar genauso, wie das schon beim Vorbild Code for America der Fall war. Redeploying, also das Ausrollen bereits anderswo erprobter Loesungen mit den Daten der eigenen Kommune, scheitert allzu haeufig an der Vielfalt der Datenformate, die aus den Fachverfahren fallen, Standardisierung ist weit weit weg, und akademische Ideen wie die Semantifizierung aller Daten sind momentan leider noch wenig praxistauglich. Zudem sind vielfach Interessierte zu einem Thema bei sich eher alleine, und andere Interessierte anderswo muessen erst einmal gefunden werden.
Umso dankbarer bin ich mittlerweile fuer die verbindende Klammer, die CfG mittlerweile bildet, und bin gespannt auf das, was da noch kommt. Ich bin unglaublich froh darueber, dass schon sehr frueh Diskussionen ueber einen Code of Conduct begonnen hatten — aus Fehlern anderer lernen, ganz angewandt. Und ich moechte mal ganz ausdruecklich ein Dankeschoen an Fiona und Julia aussprechen, die sich nun ueber ein Jahr lang um Vernetzung, Bereitstellung passender Werkzeuge, und das Ruehren der Werbetrommel gekuemmert haben.
Auf das naechste Jahr! Und noch viele kommende Open-Data-Wochenenden 😉
Vergangenes Wochenende war ich bei Workshops von Code for Germany und Code for All; am Montag startete Code for Germany offiziell; und danach war OKFest in Berlin.
Anlaesslich dieser Veranstaltung wurden Dinge gesagt, getan und geschrieben, die ich nicht unkommentiert stehen lassen moechte.
Erstens.
Ich halte die Initiative „Code for Germany“ fuer wertvoll, auch wenn ich den Namen nicht mag. Wir in Ulm coden nicht „fuer Germany“ und wir coden eigentlich auch nur deswegen „fuer Ulm“, weil wir zufaellig dort wohnen und das das naheliegendste Einsatzgebiet ist.
Der Witz an der Sache ist meines Erachtens genau nicht nur „fuer Ulm“ oder „fuer Germany“ zu entwickeln, sondern die Ideen anderer ueberhaupt erst zu entdecken und auf die eigene Situation anpassen zu koennen – und dass Ideen aus der eigenen Stadt anderswo aufgegriffen werden. Oder dass wir fuer die Ulmer Kita-Karte nun auf einen Kartendienst aus dem Berliner Lab zurueckgreifen konnten (danke, Jochen!)
Und nicht zuletzt habe ich es als unglaublich motivierend empfunden, festzustellen, dass es auch anderswo gleichgesinnte gibt, die fuer dieselben Dinge brennen. Vor allem nicht nur in Berlin.
Zweitens.
Ich konnte mich schon auf der Launchveranstaltung nicht beherrschen und habe Seitenhiebe auf einen vorangegangenen Redner abgefeuert, der den Hauptvorteil offener Daten darin zu sehen schien, Geschaeftsmodelle zu entwickeln, um die von ihm zitierten 33 Millionen EUR Wert pro Jahr aus den Berliner Daten abzuschoepfen. Wir bei der datalove-Gruppe haben kein Geschaeftsmodell. Wir haben das bislang gemacht, weil es Spass macht, weil wir Probleme loesen und die Welt zu einem besseren Ort machen wollen.
Dass das in die klassische kapitalistische Logik nicht so recht passen will, ist bedauerlich. Den Ausweg sehe ich aber nicht darin, immer noch mehr Startup-Ideen anzukurbeln und aus der Herzenssache einen Brotjob zu machen zu versuchen – und ja, auch ich bin dem Google-Sponsoring fuer codefor.de gegenueber skeptisch, auch wenn ich gerade deutlich zu nuechtern bin, das so auszudruecken wie Stefan Schulz in der FAZ.
Ich fand es aufschlussreich, wie viele der anderen Workshopteilnehmer_innen mir am Wochenende zustimmten, dass der Traum doch eine 20–30h-Woche in einem schoenen Beruf waere, der fuer Wohnung, Essen und Mobilitaet sorgt – und die restliche Freizeit kann dann mit Weltverbesserung gefuellt werden.
Dass so etwas in der Praxis nur einer kleinen Elite vergoennt ist, ist mir schmerzlich bewusst. Aber wenigstens liesse man sich auf diese Tour weder so einfach zum “useful idiot”¹ machen, noch muesste man irgendwelchen Investorengeiern hinterherlaufen. Sondern koennte wirklich an dieser Weltverbesserung arbeiten.
Weswegen. Drittens.
Ich gerne die Gruppe vorwiegend weisser, maennlicher Informatiker, die zumindest das Ulmer Lab momentan praegen, stark erweitern wuerde – mit der bestehenden Gruppe als Kristallisationspunkt, um den herum neue, interessante Dinge entstehen.
Das Laboradorio Para La Ciudad ist ein herrliches Beispiel dafuer, wie das aussehen kann: Im Vordergrund steht der Lebensraum Stadt und die Menschen, die ihn bewohnen, und sie sind es auch, die ihre alltaeglichen Probleme am besten kennen. Im Idealfall steht hinter allen Projekten auch das Ziel, die BewohnerInnen selbst zur Umsetzung der Loesungen zu ermaechtigen – Code Literacy als Auftrag, angefangen von SchuelerInnen bis ins dritte Lebensalter.
Das wuerde erstens helfen, dass nicht wie bisher alle Projekte auf den Schultern immer derselben wenigen Aktiven ruhen; zweitens deutlich vielfaeltigere Problemlagen erschliessen; und drittens einem deutlich groesseren und breiteren Bevoelkerungsquerschnitt den Zugang zu moeglichen Loesungen verschaffen.
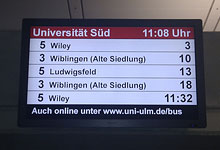
Apart from the cool technical solution the two came up with, this monitor is also interesting from yet another perspective. KVV, Karlsruhe’s integrated transit system, uses EFA by mentzDV for their online journey planner, which is in turn parsed for the display hack. EFA can output XML or JSON (depending on the installation), and the datalove working group used the EFA XML output for their own transit displays at ulm university (see below) – or for your own desktop, or for your smartphone.
Now, neither the departure monitor, nor the smartphone version, are works of art. They have severe usability and UI issues, and the EFA wrapper, while a cool hack by @taxilof, is tailored towards DING, our integrated transit system. Also, all of the systems completely rely on EFA – thus, whenever EFA fails or has scheduled downtimes, all displays fail.
I would love to bring together all interested parties who have hitherto put some efforts into any wrappers, libraries or solutions for EFA and create a unified and good library for EFA that is interchangeable to whatever version your local authority is running – just insert the API endpoint, choose whether it can output JSON or XML, and be a happy camper. Bonus points for also integrating GTFS as a fallback solution[1]!
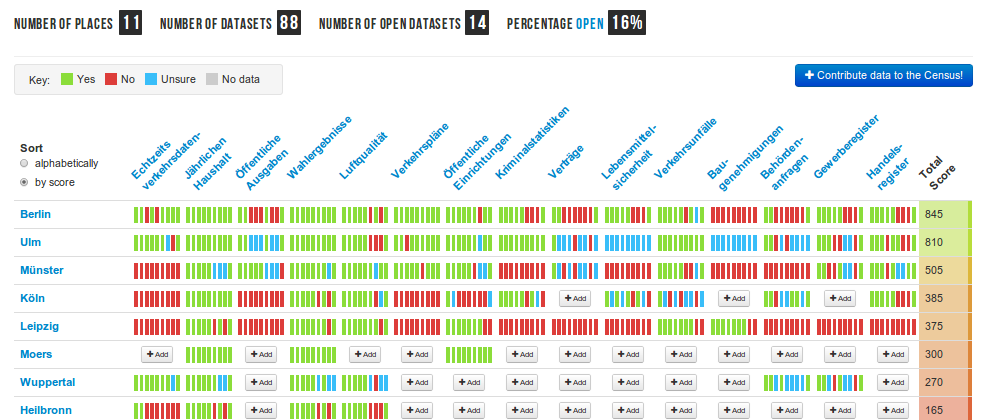
Bei dieser „Volksdatenzaehlung“ wird nach einigermassen standardisierten Kriterien abgefragt, welche Stadt welche Daten in welcher Form veroeffentlicht. Von Nahverkehrs-Echtzeit- und — missverstaendlicherweise „Verkehrsplaene“ genannten — -Sollfahrplandaten geht es ueber Haushalts-, Wahlergebnis- und Unfalldaten bis zum Gewerbe- und Handelsregister. Ein paar Punkte gibt es, wenn die Daten ueberhaupt irgendwo digital verfuegbar sind, deutlich mehr punkten kann eine Stadt, wenn sie auch maschinenlesbar, entgelt- und diskriminierungsfrei allen unter freier Lizenz zur Verfuegung gestellt werden. Open Data eben.
„Einigermassen standardisiert“ heisst hier, dass die Kriterien bei der Eintragung nicht immer ganz klar waren. Hier duerfte es stellenweise fuer dieselbe Art der Bereitstellung unterschiedliche Einschaetzungen fuer „Ja“, „Nein“ und „Unbekannt“ (respektive Gruen, Rot und Blau) zwischen den Staedten geben.
Dennoch: Das kleine, beschauliche Ulm war am Ende des ODD nicht nur die zweite Stadt, deren Datenbestand vollstaendig im Census kartiert war, sondern landete mit 810 Punkten nur knapp hinter Berlin (845 Punkte). An vielen Punkten laesst sich momentan nicht so einfach drehen – die Luftdaten kommen beispielsweise von der LUBW, da kann die Stadt nicht so viel ausrichten, selbst wenn sie wollte.
Die Stadtwerke koennten aber beispielsweise das momentan noch notwendige Formular vor dem Download der GTFS-Daten optional machen, und der Verbund koennte die Inhalte seiner Echtzeitauskunft unter freie Lizenz stellen, dann duerfte Berlin bereits ueberholt sein. Als weiterer Schritt kaeme beispielsweise die Bereitstellung von Informationen ueber Baugenehmigungen in Frage.
Es blieb aber nicht beim Census: Quasi als Fingeruebung versuchten wir uns an einer Visualisierung der freien KiTa-Plaetze in Ulm. Bedauerlich ist an dieser Visualisierung vor allem, dass das alles so viel einfacher waere, wenn die Daten nicht haendisch von der Website abgegrast werden muessten, sondern ebenfalls als „richtiger“ Datensatz mit einer definierten Schnittstelle fuer die veraenderbaren Daten (freie Plaetze) bereitstehen wuerde.
Aber Ulm macht sich ja bereits – so etwas ist dann hoffentlich nur noch eine Frage der Zeit. Oder, liebe Stadt? ODER? 😀
tl;dr vorneweg: Wir waren am Donnerstag beim DING-Verbund, am Freitag war ich beim VBB in Berlin, und die SWU geben ihre Fahrplaene als GTFS frei. Hurra!
DIVA-Allueren
Auf Einladung von Martin Schiller vom DING waren Fox und ich am Donnerstag beim DING als „unserem“ Nahverkehrsverbund zu Besuch und haben uns deren Software zeigen lassen. In Deutschland gibt es nur wenige grosse Player auf dem Markt fuer Fahrplanungs- und Auskunftssysteme, beispielsweise HaCon (HAFAS) und MentzDV (DIVA und EFA), wobei in BaWue hauptsaechlich DIVA fuer die Fahr-, Dienst- und Umlaufplanung und EFA fuer die elektronische Fahrplanauskunft zum Einsatz kommen.
Und wie das in einem kleinen Markt so ist, reissen die dazu gehoerenden Softwareloesungen nicht gerade vom Hocker. DIVA verwendet in Version 3 als Datenbackend nicht etwa einen Standard wie VDV-45X, sondern ein eigenes Textdateiformat, das ich auch nach laengerem Betrachten noch nicht so recht umrissen habe. In DIVA 4 soll wenigstens eine Datenbank im Hintergrund laufen, auf die neue Version seien bislang aber wohl nur wenige Verkehrsverbuende und -betriebe umgestiegen.
Verkehrsbetriebe benutzen solche Planungssoftware ohnehin erst ab einer bestimmten kritischen Groesse ihres Betriebs. Viele der kleineren Dienstleister verwenden entweder ganz andere Umlaufplanungssoftware, oder machen das gar von Hand oder in Excel. Der „einfache“ Transfer von DIVA zu DIVA kommt hier bei uns nur zwischen Stadtwerken und DING zustande, kleinere Anbieter auf dem Land schicken ihre Plaene im besten Fall per XLS, im schlimmsten in sonstigen semistrukturierten Formaten.
Eine weitere Hoffnung fuer den Export der Fahrplaene nach GTFS war, die Daten aus der Datenhaltung der Elektronischen Fahrplanauskunft (EFA) herauszubekommen. Die ist aber nicht minder… spannend. Die Dateien sehen wie Binaerblobs aus, und die EFA selbst ist ein Konglomerat zusammengeflanschter Module, die sehr nach historischem Wachstum aussehen. Die Echtzeitauswertung heisst beispielsweise „rud“ und lehnt sich damit noch ans Projekt RUDY an, das 2004 zu Ende ging. Und zwischendrin poppen auf dem Windows-Server-Desktop, auf dem die EFA laeuft, Adobe-Distiller-Fenster auf, wenn irgendjemand einen PDF-Fahrplan erstellt.
Spaetestens an der Stelle stellte ich mir dann schon die Frage, ob man mit geeigneten freien Software-Werkzeugkaesten nicht viel reissen koennte in diesem Orchideensektor 😀
Nichtsdestoweniger, der Ausflug war interessant, und zeigte auch, dass die CSV-Dateien, die wir von den Stadtwerken bekamen, genauso fuer den gesamten Verbund (und einigem haendischen Aufwand) aus DIVA exportiert werden koennten. Das waere aber tatsaechlich nicht unbedingt die Loesung, sondern vermutlich erst der Anfang weiterer Probleme, angefangen vom Unterschied zwischen Planungs- und Repraesentationsliniendarstellungen bis hin zu eindeutigen Schluesseln fuer Haltepunkte.
Aufgrund meiner etwas unguenstigen Anreise (siehe Trampbericht unten) kam ich leider erst nach der ersten Projektvorstellungsrunde in den VBB-Raeumen am Bahnhof Zoo an, war aber sehr angetan vom grossen Andrang dort. Neben OKFN und VBB sassen dort Leute von der BVG, jemand von HaCon war eigens angereist, und ich konnte neben „alten Bekannten“ auch endlich mal Michael Kreil und anderen persoenlich die Hand schuetteln.
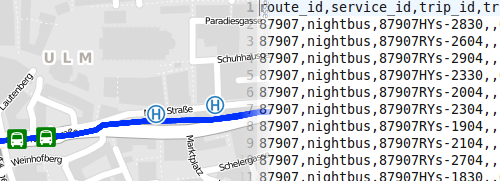
Eine ganz persoenliche Freude war mir, dort spontan eine Botschaft verkuenden zu koennen, auf die ich lange gewartet hatte: Auf der Anreise bekam ich den Link zum Datenauskunftformular der Stadtwerke Ulm zugeschickt, die wir nun ueber mehrere Monate lang begleitet haben, um ihre Soll-Fahrplaene nach GTFS zu exportieren. Leider mit einem Formular zum verpflichtenden Ausfuellen, aber das war ich dann doch durchaus bereit in Kauf zu nehmen, nachdem im Gegenzug die ODbL als Lizenz gewaehlt wurde 🙂
Es werden sich jetzt sicherlich nicht auf einmal™ tausende EntwicklerInnen auf den Ulmer Fahrplan stuerzen. Auch in Berlin passierten seit der Veroeffentlichung des VBB keine Instant-Wunder. Aber das ist meines Erachtens ein bedeutender Schritt und hoffentlich positive Signalwirkung fuer andere Verkehrsbetriebe, ebenfalls die Daten bereitzustellen.
Dementsprechend haben wir nach der Vorstellung das Ganze noch im OKF-Buero (siehe Bild) mit Mate und spaeter Bier begossen und uns noch solange darueber unterhalten, wie man das Thema weiter beackern koennte (wissenschaftliche Aufarbeitung, Hinweis auf das Kundenbindungspotenzial unabhaengiger Apps), bis ich endgueltig koerperlich so fertig war, dass ich mich endlich mit Gastgeber @_HeBu treffen musste, um unfallfrei ins Bett zu kommen.
(Das wurde dann durch einen Spaetibesuch und tags darauf durch einen Doener- und Spaeti-Besuch erfolgreich unterbunden. Trotzdem Danke, HeBu, fuer die neuerliche Gastfreundschaft und den ausgezeichneten Vanillequark von Butter-Lindner :D)
Trampstatistik
Hinweg:
Abfahrt Rosengasse mit der Linie 4 um 0706 Uhr(?), Ankunft Eichenplatz 0716 Uhr, wo nix los war.
Eichenplatz ab 0742 Uhr (26 Minuten) mit Margarete ehemals aus der Nachbar-WG, die anbot, mich generell unter der Woche immer um die Zeit auf die Lonetal nehmen zu koennen. Cool.
Ankunft auf einer total verlassenen Lonetal Ost um 0759 Uhr. Erst an der Ausfahrt gestanden, dann angequatscht, trotzdem erst um 0900 Uhr weiter (61 Minuten). Dafuer im Geschaeftsauto im Tiefflug, 137 km in 67 Minuten.
Kammersteiner Land Sued an 1007 Uhr, wenig los, angequatscht, 1047 mit 120 km/h und haeufigen Raucherpausen weiter (40 Minuten)
Taktischen Fehler begangen, nicht waehrend der Mittagessenspause meiner Fahrerin in Frankenwald Ost einen neuen Lift zu suchen.
Michendorf Süd an 1605 Uhr, machte mal eben 5:18h fuer 408 km. Trotz guter Unterhaltung etwas schade.
Weiter um 1620 (15 Minuten) bis zur U Kurfuerstenstrasse um 1710 Uhr, Fussmarsch bis zum Bf Zoo/VBB.
Rueckweg:
Aufbruch bei HeBu mit der S1 ab Wollankstrasse um 1313, S Johannissee an 1400 Uhr. An der Grunewald erst ein wenig rumgeschaut und angequatscht, das lief aber nicht. Also um 1430 mit Schild „Muenchen A9“ ab auf die Rampe, 1440 Lift bekommen 🙂
Fraenkische Schweiz/Pegnitz West an 1730 Uhr, d.h. 362 km in 2:50 Minuten und hervorragender Unterhaltung waehrend der Fahrt ueber die Unterschiede zwischen PaedagogInnen und ErzieherInnen 😀
Sanifair-Gutscheine gegen Burger getauscht, 1750 mit Schild „Ulm“ an die Ausfahrt gestellt, 1804 Lift bis Bahnhof Heidenheim angeboten bekommen. Da sagt man nicht nein 🙂
Bf Heidenheim an 1942, 197 km in 1:38h. Das waren rekordverdaechtige 5:12h von Grunewald bis Heidenheim, und selbst mit S-Bahn vorneweg und den 50 Minuten Regionalexpress nach Ulm am Ende gerade mal 45 Minuten langsamer als ein ICE gewesen waere 😀