Je laenger ich Wikidata und die Konzepte von Linked Open Data und was alles dazugehoert kenne, desto faszinierter werde ich davon. Derweil brauchte ich wirklich lang, um das zu verstehen – bei meinem ersten Kontakt 2012 war ich etwas ratlos, die deutschlandweiten Wikidata-Workshops im damaligen Verschwoerhaus ab 2016 haben wir das aber umso naeher gebracht, und spaetestens ab ca. 2019 war ich bei meiner Erkundungswanderung durch die Ulmer Stadtverwaltung ueberzeugt: Wer Open Data haben will, muss Linked Data mitdenken – alles andere ist Augenwischerei.
Leider ist es nicht ganz so leicht, sich in die Thematik einzuarbeiten. Ich habe die letzten Wochen aber zwei Hilfestellungen gefunden, die das vielleicht erleichtern koennten. Das schlimme ist ja, dass man das kaum mehr einschaetzen kann, sobald man selbst nahe genug dran ist – von aussen wirkte alles hoechst kryptisch und verschlossen und unverstaendlich. Hat man die Schwelle aber einmal ueberschritten, ist ja alles klar.
Denny Vrandečić, Lydia Pintscher und Markus Kroetzsch haben auf The Web Conference 2023 ein Paper zur Geschichte von Wikidata veroeffentlicht und es gibt die Inhalte auch in einem unterhaltsamen Video:
Ausserdem laeuft aktuell ein wie ich finde gut gemachter MOOC-Selbstlernkurs des Hasso-Plattner-Instituts zu Knowledge Graphs. Die Teilnahme ist kostenlos, und wer jetzt sofort mitmacht, kann auch noch die bewerteten Zwischenuebungen mitmachen. Was ich bislang gesehen habe, gefaellt mir sehr gut und stellt auch gelungen die Verbindungen zwischen den abstrakten Konzepten von Knowledge Graphs, dem Semantic Web Stack und den urspruenglichen Ideen des Semantic Web her – das ist etwas, was beim 5-Sterne-Modell teilweise zu implizit angenommen wird.
Das ist aus zwei Gründen bemerkenswert. Erstens wegen des GovTech-Campus selbst, seiner Organisation als eingetragener Verein, in dem Unternehmen für mehrere tausend Euro Mitglied werden können, und der Tatsache, dass dort Ministerien und privatwirtschaftliche Dienstleister unter demselben Dach sitzen und „gemeinsam“ IT-Dienstleistungen entwickeln. Die Lage hebt das als positives Beispiel hervor. Zweitens, weil eher im Nebensatz erwähnt wird, dass es seit vielen Jahren auch eine aktive digitale Zivilgesellschaft in diesem Bereich gibt. Die ehrenamtliche Zivilgesellschaft hat im Konzept des GovTech-Campus aber gar keinen Raum, und wird in der Lage auch nur im Rahmen von Hackathons erwähnt, die an den Bedürfnissen vorbei entwickeln würden.
Derweil kann man argumentieren, dass die Situation, in der die öffentliche Hand bei ihren Digitalisierungsbestrebungen stets auf externe Dienstleister angewiesen ist und mit der Zivilgesellschaft allenfalls im Rahmen von Hackathons interagieren kann, eine Konsequenz des New Public Management ist. In diesem Denkmodell wird die Bevölkerung zu „Kund*innen“ des Staats, der sich – auch in genuinen Aufgaben der Daseinsvorsorge – wie ein Unternehmen verhalten soll. Das heißt zum Beispiel, dass Abteilungen sich untereinander ihre Leistungen in Rechnung stellen. Aber auch, dass Leistungen der öffentlichen Hand an Unternehmen oder eigene Gesellschaften ausgelagert werden. Ein Engagement außerhalb dieser Wirtschaftslogik ist gar nicht vorgesehen – das heißt, die umfangreiche praktische Digitalisierungsexpertise aus dem Ehrenamt zerschellt regelmäßig an der staatlichen Organisationspraxis.
Schon für die Anforderungsbeschreibung von Digitalprojekten braucht es externe Beratung
Wünschewand beim OpenCityCamp 2012
Das hatte gerade für die Digitalisierung fatale Folgen. Anstatt IT-Architekturkompetenzen auf allen Ebenen der föderalen Verwaltung aufzubauen, bestimmt seit Jahren eine Reihe externer Dienstleister, wohin der Staat digitalisiert. Was auf den ersten Blick wie eine Effizienzsteigerung klingt – denn natürlich sollen nicht über 11000 Kommunen jeweils ihre eigene Softwarelösungen entwickeln – führte über die Jahre zu einem weitreichenden Kompetenzverlust schon bei der Bestimmung, was eigentlich die Anforderung an die zu bauenden Softwarearchitekturen sind. Als Nebeneffekt kann es dann auch schon einmal vorkommen, dass die beschaffte Software am Ende gar nicht für den gedachten Einsatzzweck taugt und das Projekt für die Katz war. Lilith Wittmann nennt das in ihrer kritischen Besprechung des GovTech-Campus die „Beratertreppe“: Die laufende Externalisierung von Kompetenzen wurde zur selbstverstärkenden Spirale, so dass seit Langem schon für die Erstellung der Ausschreibungen für ein Softwareprodukt externe Beratung herangezogen werden muss.
Diese Erfahrung haben in den vergangenen Jahrzehnten auch immer wieder Ehrenamtliche aus der Zivilgesellschaft gemacht. Analog zur Civic-Tech-Bewegung in den Vereinigten Staaten entstanden in den späten 2000er-Jahren auch in Deutschland Gruppen Freiwilliger, die am praktischen Beispiel aufzeigten, was mit den Mitteln der Informationstechnik eigentlich möglich wäre. Als Instrument der Selbstermächtigung und zivilgesellschaftlichem Gegenstück zu Open Government entstanden Transparenz fördernde Auswertungen offener Daten, aber auch ausgereifte Beispiele, wie die öffentliche Hand ihre Leistungen für die Bevölkerung noch besser benutzbar machen kann.
All diese Gruppen stießen jedoch früher oder später auf die immer selben strukturellen Hürden, wenn es darum ging, dass der Staat ihre Ideen auch aufgreift und sich zu eigen macht. In ihrem Buch „A civic technologist’s practice guide“ beschreibt die ehemalige leitende 18F-Mitarbeiterin Cyd Harell zwei notwendige Schritte für die erfolgreiche Anwendung von Civic Tech: „Showing what’s possible, and doing what’s necessary“. Dieser Pfad, dass Ehrenamtliche aus der Zivilgesellschaft zeigen, was möglich wäre, und der Staat dann das Notwendige tut, um sich diese Beispiele zu eigen zu machen, scheint in Deutschland aber fast nirgendwo vorgesehen zu sein. Meist ist man entweder zivilgesellschaftliche „Kund*in“ des Staats und kann allenfalls im Rahmen von Anhörungen und Feedbackrunden Jahr für Jahr dieselben Post-Its auf Metaplanwände kleben – oder man muss selbst Dienstleister*in werden und sich beauftragen lassen, der eigenen Idee irgendwo im Wildwuchs der Verwaltungs-IT ein Gärtchen bestellen zu dürfen.
Für gestaltende Zivilgesellschaft ohne wirtschaftliches Interesse gibt es in diesem Denkmodell keinen Raum
kleineAnfragen.de: 2014–2020
Für die Unterstützung der Umsetzer-Rollen gab es über die Jahre verschiedene Ansätze: Inkubatorprogramme, Förderlinien, Kooperationen mit Umsetzungspartnern aus der Wirtschaft. Das waren aber allesamt lediglich unterschiedliche Geschmacksrichtungen entweder von Firmengründungen oder kurz- bis mittelfristigen finanziellen Förderungen, damit Weiterentwicklung und vor allem Wartung und langfristiger Betrieb wenigstens nicht in der Freizeit der Beteiligten passieren musste. Wir haben im Ergebnis bis heute keinen Ansatz, um langfristig einen Pfad zu ebnen, dass die öffentliche Hand selbst fertige, von der öffentlichen Hand direkt übernehmbare Produkte wie kleineanfragen.de auch selber betreiben könnte, und sei es über Konstrukte wie die kommunalen Rechenzentrumsverbünde. An die Stelle von Civic Tech aus einer engagierten Bürgerschaft und einer Verwaltung, die selbst in der Lage ist, aus deren Erfahrungen zu lernen, ist GovTech getreten – also die vollständige Abhängigkeit von Firmen, die teils den Staat als einzigen Kunden für ihre Produkte haben.
Das ist auch eine Erfahrung der Zivilgesellschaft aus jahrelanger Beschäftigung im Austausch mit der Verwaltung – sei es bei selbst organisierten Barcamps oder der Beteiligung an Hackathon-Formaten. Und hier zeigt sich eine weitere problematische Konsequenz dieser Kompetenzauslagerung durch den Staat. Eher im Nebensatz erwähnt Philip Banse, dass es neben dem ebenfalls auf dem GovTech-Campus vertretenen Digital Service des Bunds auch Ehrenamtsnetzwerke wie Code for Germany gebe – aber die würden ja eher Hackathons machen und an den Bedarfen der öffentlichen Hand vorbei entwickeln.
Aus Sprints werden Marathons – aber warum sollen Ehrenamtliche laufen, und nicht der Staat?
Indes waren es gerade die Ehrenamtlichen des Code-for-Germany-Netzwerk, die auf den Nachhall des großen Corona-Hackathons der Bundesregierung 2020 in Form einer Wiederentdeckung von Hackathons durch die öffentliche Hand und seinen Partnerorganisationen wie Tech4Germany (aus dem der oben erwähnte Digital Service hervorging) eher verhalten reagierten. Viele der Code-for-Germany-Aktiven haben über die Jahre hinweg Begegnungen mit Hackathonformaten gehabt – und merkten über die Zeit, dass sie zwar an Erfahrung dazulernten, wie die Verwaltung funktioniert, aber immer wieder auf dieselben Probleme und Hilflosigkeiten dieser Verwaltung stießen, die schon auf den Austauschformaten mehrere Jahre zuvor adressiert werden sollen hätten. Die Erfahrung der Code-for-Germany-Ehrenamtlichen zeige, „dass es weniger um die Prototypen als viel mehr [um] Erkenntnisse auf einer strukturellen Ebene“ gehe, heißt es in einer Handreichung des Netzwerks vom Sommer 2020.
Zum einen geht es bei Hackathons wegen des immer noch vielfach genutzten Wettbewerbscharakters nämlich viel zu häufig um den Start neuer Projekte. Häufig werden also Ideen neu erfunden, an denen andere Gruppen bereits – beispielsweise aus eigener Betroffenheit – zur Verbesserung einer konkreten Situation gearbeitet haben und nun Unterstützung zur Weiterentwicklung und Wartung gebrauchen könnten. Zum anderen laufen auch die „Verstetigungsprogramme“ bis heute meist auf die finanzielle Unterstützung der Ideengeber*innen oder die Entwicklung der Ideen in ein Geschäftsmodell hinaus. Aus dem Sprint werde ein Marathon, hieß es im Nachgang des Corona-Hackathons – ohne dabei die Frage zu stellen, warum denn nun ausgerechnet die Zivilgesellschaft einen Marathon laufen soll, und nicht der Staat.
Die ausgearbeiteten Lösungen aus dem Digitalen Ehrenamt liegen meist schon vor – haben aber selten Chance, zu verfangen
So stellte eine Kommune die Herausforderung vor, die Beschlüsse des Gemeinderats „erlebbarer, einfacher auffindbar und transparenter“ zu machen. Das Ratsinformationssystem der Kommune habe in der Regel Schnittstellen, um diese Informationen abrufen und beispielsweise auf einer Karte darstellen zu können. Bei der beschriebenen Schnittstelle handelt es sich um den seit 2012 durch Ehrenamtliche bei Code for Germany entwickelten Standard OParl. Und die Ironie der Challenge ist, dass, wie gerade erst von Nora Titz beschrieben, am Anfang dieser Standardisierung genau solche grafischen Aufbereitungen der Ratsinformationen standen – damals mit Scrapern aus den Informationssystemen extrahiert und beispielsweise auf Karten dargestellt. Die für die Öffentlichkeit nutzbaren, im Ehrenamt entwickelten Frontends für die Auswertung der OParl-Daten konnten bis heute nicht von der öffentlichen Hand übernommen, geschweige denn betrieben werden. Teilweise scheint es ihr schon schwerzufallen, die beim Ratsinformationssystem-Anbieter bestellte OParl-Schnittstelle auch auf ihre korrekte Installation zu überprüfen und abzunehmen. Die OParl-Schnittstelle der Challenge-gebenden Stadt war zum Zeitpunkt des Hackathons gar nicht aktiviert – und ist es auch zum Zeitpunkt dieses Artikels noch nicht. Es existiert zwar ein fertiges Validierungsskript, mit dessen Hilfe man die Standardkonformität der Schnittstelle in Minutenschnelle prüfen kann. Um dieses Skript bei der Abnahme im Verwaltungsnetz ausführen zu können, bedarf es aber der internen Fähigkeiten, den Validator auf Verwaltungsrechnern selbst zum Laufen zu bringen. Danach braucht es noch etwas Verständnis, die Ausgaben interpretieren zu können und sich vom Dienstleister nicht einreden zu lassen, dass der Fehler bei einem selber liege. Was engagierten Freiwilligen mit grundlegenden Kenntnissen eine spielerische Fingerübung weniger Minuten ist, stellt die Verwaltung teilweise heute noch vor große Herausforderungen. Der Staat baut hier nicht die notwendigen Kompetenzen in der Breite auf, um die gratis vom Ehrenamt gelieferten Skripte auch selbstbestimmt ausführen zu können. Stattdessen sind diese Ehrenamtlichen letztlich dazu gezwungen, selbst als bezahlte Dienstleister*innen aufzutreten, wenn sie wollen, dass ihre Ideen auch in die Tat umgesetzt werden.
Vorhandenes Wissen aufgreifen und dokumentieren – nach den Bedürfnissen des Ehrenamts!
Die überstarke Begeisterung des Staats für Hackathons scheint mittlerweile – zum Glück! – endlich abzuflauen. Offen bleibt aber die Frage, wie Ehrenamt und Zivilgesellschaft sich überhaupt wirkungsvoll mit ihrer Expertise einbringen können. Der Anspruch kann dabei nicht sein, auch als Zivilgesellschaft ein Büro am GovTech-Campus zu haben. Schon die Existenz eines GovTech-Marktes ist mehr Indikator eines grundsätzlichen Problems, als dass diesem Markt mit einem Austauschcampus noch niederschwelligerer Zugang geschaffen werden soll. Es kann auch nicht die Aufgabe Ehrenamtlicher sein, werktags mit am Tisch zu sitzen, wenn Vergabeverfahren für staatliche IT-Lösungen nun möglicherweise noch weniger nachvollziehbarer als bisher zwischen Verwaltung und Dienstleistern ausgehandelt werden. Vielmehr geht es darum, den Wissensschatz der ehrenamtlichen Digitalen Zivilgesellschaft aktiv zu suchen und in die Verwaltung selbst zu transferieren.
Wikimedia Deutschland hat gemeinsam ergänzt um Interviews mit der Deutschen Stiftung für Ehrenamt und Engagement vergangene Woche im Politikbrief „Digitales Ehrenamt: Zivilgesellschaftliche Teilhabe im Digitalen Raum“ sechs Forderungen aufgestellt, wie dieses Engagement besser vom Staat gewürdigt und gefördert werden sollte. Eine der Forderungen ist der systematische Transfer ehrenamtlicher Expertise. Der Staat sollte nicht etwa Dienstleister*innen auf seinen GovTech-Campus zu sich einladen und damit weiter Kompetenzen externalisieren, sondern strategisch interne IT-Fähigkeiten aufbauen. Das vorhandene Wissen im digitalen Ehrenamt muss durch aufsuchende Beteiligung und den Bedürfnissen der Freiwilligen folgend aufgegriffen und dokumentiert werden, um es verwaltungsintern verwendbar und anwendbar zu machen. Damit könnte endlich eine Brücke über die nach wie vor bestehenden Wissensklüfte geschlagen werden – damit kommende Generationen ehrenamtlich Aktiver hoffentlich künftig nicht mehr zu ihrer Frustration auf dieselben strukturellen Hürden stoßen, an denen diese Partizipation bislang scheiterte.
//edit am 24. Januar 2023, Rolle der DSEE im Politikbrief von WMDE korrigiert
Ab 09:27 kommt im Video ein anschauliches Beispiel des dahinter liegenden Paradigmenwechsels. Anstelle von Apps, die auf hardcodierte APIs zugreifen muessen (und die dann wieder angeflanscht an zentralisierte Datensilos sind), werden Abfragen im dezentralen Modell lokal synthetisiert. Die notwendigen Daten kommen dann aus denjenigen verteilten Quellen, die fuer genau diese Frage notwendig sind.
In Ergaenzung (und technisch notwenige Voraussetzung) zum auf den Kopf gestellten Nutzungsversprechen von Open Data erlaubt diese Herangehensweise eine Abkehr von zentralisierten Superdatenplattformen. Die bisherige Idee war, dass es ja eine Vielzahl von Fachverfahren gebe, deren Daten in einzelnen Silos liegen. Um das aufzubrechen muessten Verfahren standardisiert werden und alle Daten in ein zentrales Silo anliefern. Was auch bedeutet, dass z.B. einzelne Kommunen oder Bezirke ihre bisherigen Fachverfahren fuer ein Thema aufgeben und sich der Mehrheit anschliessen muesten – und sei es mit Zwang. Im Gegenmodell waere die interne Datenhaltung oder zumindest das Ergebnis eines ETL-Prozesses der Fachverfahrensdaten ein Knowledge Graph – und ueber verteilte Knowledge Graphs lassen sich wie im Video demonstriert wunderbar Abfragen fahren, nur durch die Magie von 5-Sterne-Daten mit Semantik. Die Bausteine dafuer sind mittlerweile Jahrzehnte alt und gut abgehangen. Und eigentlich passt das auch viel besser in das Modell eines foederalen Staats, der nicht alles von oben her vereinheitlicht und nach oben hin an sich zieht, sondern auf den Ebenen auch Entscheidungsspielraeume laesst.
Lilith Wittmann ist wie immer gleich deutlich radikaler und sagt: Alles bis drei Sterne sollte eigentlich gar nicht mehr zaehlen, wir muessten noch weiter gehen und Open Data erst ab vier Sternen ueberhaupt „zaehlen“ lassen:
Das Problem ist aber: Wir haben seit 15 Jahren dieselbe Vision, bei der alles ab Schritt 4 in weiter Ferne erscheint. Und gerade in Deutschland kam nie irgendwas über 3⋆ hinaus.
Deshalb schlage ich heute eine neue Version von 5⋆ #OpenData vor.
Toris Post war mir jetzt endlich aufraffender Anlass, verschiedene Textstuecke zusammenzustellen, die ich seit einer Weile vor mir herschiebe, und im Mai war das nun endlich alles so weit, dass ich einen ersten Entwurf beim Kommunalen Open Data Barcamp vortragen konnte. Denn dieser Fokus „die oeffentliche Hand soll Open Data bereitstellen, damit Dritte irgendetwas damit tun“ ist einer der fundamentalsten Missverstaendnisse des letzten Jahrzehnts in dieser Szene. Und ich fuerchte, dieses Missverstaendnis sabotiert seit Jahren die eigentlich anzugehenden Aufgaben.
Eine Quelle dieses Missverstaendnis koennte das typische “Showing what’s possible“-Muster aus dem Digitalen Ehrenamt sein. An einem konkreten Beispiel wird gezeigt, was mit offenen APIs und/oder offenen Daten oder einem besseren User Interface moeglich waere. Dabei ist beinahe egal, ob man nun einen bestehenden Dienst besser macht (wie z.B. kleineanfragen.de das tat), oder ob man an einem ganz konkreten Beispiel (fuer das man irgendwie an Datenpunkte kam) ein anschaulich nutzbares Produkt baut, wie die Trinkwasser-App.
Ende November hatten wir im Netzwerk Code for Germany einmal versucht, typische Aktivitaeten der lokalen Open-Data-Arbeitsgruppen einzuordnen, und an vielen Stellen kam dieses „showing what’s possible“ zur Sprache. Menschen machen das aus den verschiedensten Beweggruenden: Weil sie selber einen praktischen Anwendungsfall fuer das Ergebnis haben. Weil sie zeigen wollen, was geht. Oder einfach auch nur aus Spass.
An vielen Orten entstanden genau so vor ca. 10 Jahren die ersten veroeffentlichten Datensaetze. In Ulm hatte die Gruppe Engagierter einzelne Datensaetze per Mail von der Stadtverwaltung erhalten, und beispielsweise die Geodaten der Stadtbezirke selber zum Download und ueber eine CouchDB ausgespielt, und in Click-that-Hood praktisch erfahrbar gemacht.
Andere Staedte sprangen auf den „Trend“ auf. Datensaetze wurden immer noch haendisch herausgesucht und veroeffentlicht – und meist orientierte man sich dabei an den Datensaetzen, die bereits anderswo veroeffentlicht oder gar in einen praktischen Anwendungskontext bezogen wurden. Und nebenbei glaubte man, dass Datenportale hermuessten, Metadatenbeschreibungen fuer jede Excel-Liste im Datenportal wurden umstaendlich gepflegt, und viel dergleichen haendische Arbeit mehr.
Auf der zivilgesellschaftlich engagierten Seite entstand dadurch der empfundene Druck, die bisherigen Konzeptprototypen und Showcases zu „redeployen“. Anderswo gab es nun auch Stadtbezirks-Geoshapes, Trinkwasserinformationen und dergleichen mehr. Also, war die Annahme, muesse man die aktuellen Daten nun auch in einen lokalen Ableger dieser Showcases einpflegen. Gleichzeitig stieg die Erwartung, dass diese Beispielvisualisierungen auch auf lange Frist unterhalten und gepflegt werden wuerden. Und an den Orten, an denen sich niemand auf die aufwaendig bereitgestellten Daten stuerzte, war die Enttaeuschung gross. Denn wofuer macht man sich ueberhaupt den Aufwand?
Eigentlich seltsam, denn die Metapher ging ja eigentlich schon lange dahin, dass die Bereitstellung offener Daten so etwas wie ein automatisierter Containerhafen werden sollte – derweil die Daten immer noch wie haendisches Stueckgut aus den Fachverfahren und Excel-Listen herausgetragen werden.
Und da sind wir eigentlich am Kernproblem: An viel zu vielen Stellen wird haendisches oder maessig automatisiertes 3-Sterne-Open-Data immer noch als akzeptables Zwischenziel angesehen.
Wir erinnern uns aus dem Covid-Daten-Beispiel: Bis zu 3-Sterne-Daten kommen als CSV daher – ohne Informationen, was eigentlich in welcher Spalte steht und was das sein soll. Ist es ein Datum? Ein Strassenname? Die Zahl der Infizierten am gestrigen Tag? Wenn ich das auswerten will, muss ich das meinem Parser erst einmal haendisch pro Spalte beibringen. Und wenn das RKI die Reihenfolge der Spalten aendert, faellt der Parser auf die Nase.
Ich glaube, dass all das damit zusammenhaengt, dass in der Regel intern gar nicht die Voraussetzungen vorhanden sind, um mit diesen Daten in groesserem Umfang etwas anzufangen. Die Listen sind Datenbasis fuer (haendisch erstellte) Reports, (haendisch erstellte) Schaubilder, aber es sind weder die notwendigen Werkzeuge noch die notwendigen Infrastrukturen vorhanden, um schon verwaltungsintern Daten ueberhaupt strukturiert abzulegen und dann an anderer Stelle damit zu arbeiten – idealerweise mit dem Ziel eines Knowlege Graphs fuer 5-Sterne-Open-Data.
Und gerade weil die notwendige Voraussetzung fuer die Herstellung eines solchen Zustands eine hervorragende IT-Infrastruktur auf dem Stand der Technik ist, muessen wir die bisherigen Herangehensweisen weitgehend auf den Kopf stellen. Bisherige Beispielkataloge, was denn ueberhaupt als Open Data veroeffentlicht werden koennte, orientieren sich meist daran, was anderswo da war. Das waren aber eben entweder die beruechtigten “Low Hanging Fruits”, oder eben Datensaetze fuer die genannten Proofs of Concept. Das ist aber meist komplett losgeloest von einer internen Nutzung, die ueberhaupt erst die Motivation und den Anlass geben koennte, die dafuer notwendigen Strukturen aufzubauen. Idealerweise wuerde eine Strategie nicht damit beginnen, die hunderten Fachverfahren zu kartieren und wie man deren Daten per ETL herauskratzen kann. Sondern (mit einer klaren Strategie zu Linked Open Data im Kopf!) praktische Anwendungsfaelle zu finden, in denen Einheit A intern Daten braeuchte, die Einheit B bislang unstrukturiert ablegt oder auf Zuruf aufbereitet – und dann beginnt, Prozesse fuer die automatische Verdatung zu bauen. Inklusive des Aufbaus der notwendigen Kompetenzen und des Unterbaus, um das selber machen zu koennen oder zumindest den Weg dahin kompetent selbst zu bestimmen. Open Data darf kein Mehraufwand sein, sondern faellt quasi als Abfallprodukt aus besseren Prozessen heraus – wer etwas veraktet, produziert automatisch Linked Data, das bereits behoerdenintern nachgenutzt werden kann. Der Open-Teil ist dann „nur“ noch eine Frage dessen, was nach aussen veroeffentlicht werden soll.
Die Digitalisierung des Gesundheitswesens ist ein Trauerspiel. Die Datenlage zu den Auswirkungen der Omikron-Welle ist ein Desaster. Dabei ist eine gute Datenlage der Dreh- und Angelpunkt im Kampf gegen Omikron, kommentiert Eva Quadbeck. https://t.co/UhTLwZHdN7
Die Digitalisierung des Gesundheitswesens sei ein Trauerspiel, titelt das Redaktionsnetzwerk Deutschland. Nachdem man dem Reflex nachgegeben hat, „was, nur des Gesundheitswesens?“ zu rufen, dachte ich mir, man koennte ja mal das mit dem Aufschreiben des besseren Gegenentwurfs machen, der mir seit Monaten im Kopf rumspukt.
Tatsaechlich beobachte nicht nur ich die (Daten)lage seit geraumer Zeit mindestens mit Irritation. Lena Schimmel schrieb kurz vor Weihnachten einen ganzen Thread, dass sie selbst erschreckend lange die eigentlich vom RKI veroeffentlichten Daten ueber Sequenzierungen gar nicht erst gefunden hatte:
Okay, das ist jetzt… peinlich? Lustig? Beruhigend? Beunruhigend? Irgendwie alles davon:
Ich hab ja kürzlich die Sequenzierungen des RKI auf GitHub gefunden und viel Arbeit hinein gesteckt, aus den Sequenzen die Varianten zu bestimmen.
Ich glaube, dass „wir“ als „die gesellschaftliche Open-Data-Lobby“ uns wieder viel viel mehr auf Linked Open Data als Ziel konzentrieren und das auch kommunizieren muessen. Bei all dem Einsatz, wenigstens CKAN oder irgendein Datenportal auszurollen, scheint das fernere Ziel ueber die Jahre immer mehr in Vergessenheit geraten zu sein.
Schon vom Nutzungsfaktor her duerfte dieses Ziel jedoch am Beispiel der Pandemie sehr klar zu vermitteln sein. Seit nun beinahe zwei Jahren setzen sich jeden Morgen viele DatenjournalistInnen an ihre Rechner und versuchen, aus den aktuellen Datenpunkten zum Infektionsgeschehen und den Impfungen Erkenntnisse zu ermitteln und diese nachvollziehbar aufzubereiten.
heute arbeite ich eigentlich nicht, aber das @rki_de fügt unnötige spalten ein, deren werte sich aus den vorhandenen daten berechnen lassen. pic.twitter.com/8uT9GarRzt
Ueber die Zeit hinweg ist es ein bisschen zu einem Running Gag geworden, dass das RKI dabei immer wieder mal Spalten vertauscht oder neue Daten hinzufuegt, so dass all die gebauten Parser auf die Nase fallen.
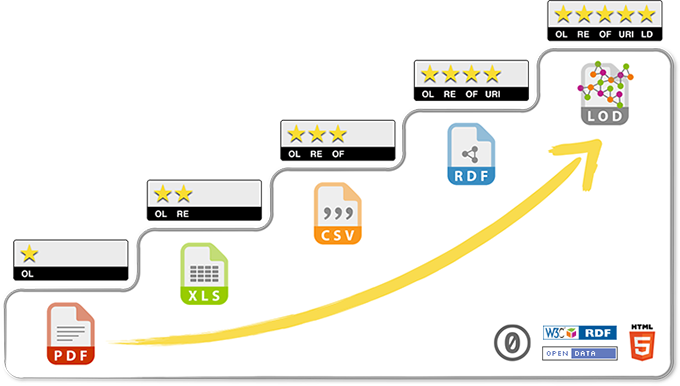
Derweil koennte die Lage mit verlinkten – oder wenigstens semantischen – Daten deutlich einfacher ablaufen. Man kann sich die 5-Sterne-Treppe fuer offene Daten am Beispiel der RKI-Berichte recht anschaulich klarmachen:
In der ersten Stufe (die Daten sind irgendwie da) sind die Informationen zwar irgendwie als digitale Symbole codiert, das kann aber auch ein PDF sein, oder im schlimmsten Fall ein PDF eines eingescannten Dokuments. Eine Maschine kann diese Symbole uebertragen und die dadurch codierten Inhalte aufbereiten und anzeigen, aber die Datenpunkte darin sind im unpraktischsten Fall nur fuer Menschen lesbar.
(Exkurs. Wenn wir ueber „Daten“ sprechen, werden schon diese beiden Definitionen haeufig wild durcheinander geworfen. Einerseits die Symbole oder „bits und bytes“, die Information codieren – so wie die Buchstaben, die diesen Satz bilden. Andererseits Datenpunkte, die z.B. verarbeitbare Information ueber einen Temperaturmesswertverlauf abbilden.)
In Stufe 2 und 3 sind auch die Datenpunkte fuer Maschinen interpretierbar, weil die Informationen mehr oder weniger strukturiert in einem proprietaeren (Excel) oder offenen (CSV) Format vorliegen. Die Zusammenhaenge bzw. die Semantik erschliessen sich jedoch immer noch nur der menschlichen Betrachterin, die diese Struktur selbst in die automatisierte Auswertung einbauen muss. Wenn das RKI ohne Ankuendigung die Reihenfolge der Spalten aendert, kann ein einmal geschriebenes Auswertungsskript diese Aenderung nicht ohne weiteres erkennen und wird erst einmal falsche Auswertungen ausgeben, bis es auf die veraenderte Datenlage angepasst ist.
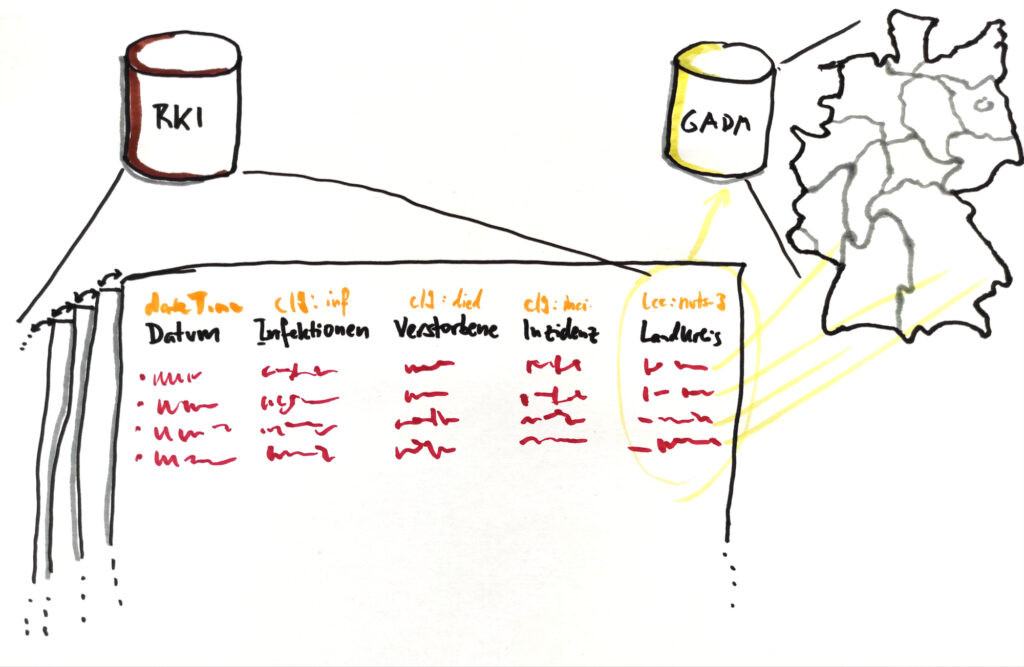
Das ist der Punkt, der in Stufe 4 behoben wird: Dann ist naemlich auch die Semantik als weitere Ebene im Datensatz codiert. Ich muss nicht mehr als auswertende Person aus dem Originaldokument in menschlicher Sprache lesen und dann fuer das Auswertungsskript festlegen, dass Spalte B das Bundesland und Spalte N die Zahl der in einem Impfzentrum vollstaendig geimpften Personen unter 60 Jahren ist. Ich muss stattdessen dem Auswertungsskript fuer das (zugegeben, einfachere) Beispiel des Bundeslands „nur“ mitgeben, dass es in irgendeiner Spalte eine Beschreibung gemaess Language, Countries and Codes (LCC) erwarten kann, und da wird dann ein passender ISO-3166-2-Code mit dabei sein. In welcher Reihenfolge die Spalten dann ankommen, und ob das jetzt der Impf- oder der Inzidenzbericht ist, spielt eigentlich keine Rolle mehr.
Die Fallzahlen kommen aus einem Repo, die Geoshapes aus einem anderen, auf das als Dependency verlinkt werden kann. Ausserdem: Ich kann keine Karten zeichnen (deswegen brauche ich Shapes)
Im Vollausbau der Stufe 5 verlinkter Daten wird vielleicht am besten deutlich, was man mittlerweile haben koennte. Anstatt dass man sich jeden Morgen ein hoffentlich aktualisiertes Excel-File der Inzidenzen und Impfinformationen herunterlaedt, reicht das Gegenstueck zu einem git pull – alles liegt als von Tag zur Tag (bzw Veroeffentlichungsschnappschuss zu Veroeffentlichungsschnappschuss) versionierter Datenframe vor. Wenn ich den Datensatz einmal ausgecheckt habe, kann ich lokal die Updates bekommen, die Unterschiede von Schnappschuss zu Schnappschuss diffen, und auch in der Historie beliebig zurueckspringen, um Zeitreihen zu machen.
Da aber sowohl die Semantik im Datensatz codiert ist, als auch Links auf andere Datenquellen vorhanden sind oder von mir hergestellt werden koennen, kann ich sehr viel mehr automatisieren, was ich sonst zu Fuss machen muesste: Wenn in irgendeiner Spalte die Landkreise mit Kreisschluessel codiert sind, und ich meine Auswertung per Karte machen will, kann ich aus einer passenden anderen Datenquelle automatisch die Geometrien des NUTS-3-Level in Deutschland laden und mit dem RKI-Datensatz verknuepfen.
Das ist jetzt rein aus der Nutzungsperspektive gesehen, weil das mit die anschaulichste ist. Eigentlich viel spannender ist aber, die Konsequenzen durchzudenken, was es bedeuten wuerde, die dafuer notwendige Infrastruktur im Betrieb zu haben. Das heisst, dass Datenpunkte und Informationen nicht haendisch in der Gegend herumgetragen und zu Fuss alleine in Excellisten vorgehalten und gepflegt werden. Dass es definierte Schnittstellen und Datenfluesse gibt, die auch die behoerdeninterne Nutzung von fuer Entscheidungen relevanter Daten erlauben, ohne dass diese muehsam und fehleranfaellig zusammengekratzt werden muessen. Und nicht zuletzt auch, dass wir dafuer die ueber Jahrzehnte aufgebauten technischen Schulden der oeffentlichen IT-Infrastruktur abgebaut und die Architektur vorausschauend sparsamer weil effizienter(!) geplant und umgesetzt haben.
Es ist total schade, dass so viele der Visionen aus den 2000ern durch das jahrelange Klein-Klein der Umsetzung, die zu schliessenden Kompromisse mit Verwaltungen, und die perverse incentives fuer „Umsetzungen“ verkaufende Dienstleister so tief in die metaphorischen Sofaritzen verschwunden und in Vergessenheit geraten sind.
The current public funding schemes geared towards “digitalization” and “innovation” constitute perverse incentives. In the long run, they are not only expensive, but will pile up massive amounts of technical debt vastly exceeding the investments. https://t.co/dsb8ovKMvq
Manches davon ist natuerlich auch mittlerweile ueberholten Ueberlegungen von damals geschuldet. In der 5-Sterne-Treppe wird beispielsweise als erster Schritt ein „OL“ angegeben, das fuer eine Offene Lizenz stehen soll. Das halte ich mittlerweile fuer ueberholt und teilweise durch die viele Wiederholung auch ein wenig schaedlich. Denn die Diskussion z.B. bei Infektions- oder Impfdaten ist eigentlich gar nicht, ob sie unter der internationalen Creative-Commons-Lizenz oder der nutzlosen und ersatzlos abzuschaffenden Datenlizenz Deutschland „lizenziert“ werden. Denn das sind Faktendaten, und die gehoeren allesamt gemeinfrei gemacht.
tl;dr: Bitte einmal Linked Open Data als Ziel, zum mitnehmen, und etwas mehr freundliche Radikalitaet.
Ich bin gerade noch einmal ueber den Vortrag „CKAN: apt-get for the Debian of Data“ vom 26C3 im Dezember 2009 gestolpert. Rufus Pollock (Gründer von Open Knowledge International) und Daniel Dietrich (Mitgruender des deutschen Ablegers, der OKFde) erklaerten damals ihre Vision eines Netzwerks von Datenquellen.
Das heute, knapp 12 Jahre spaeter noch einmal anzusehen, war… spannend. Ich zucke heute ueber das “this is when nerds run things” am Anfang peinlich beruehrt zusammen, aber es lohnt sich total, noch einmal aufzurollen, was in der Zwischenzeit alles (nicht) passiert ist:
Der gesamte Vortrag denkt in (vermeintlich) notwendigen Lizenzen fuer Daten – “Free Data“ von Denny Vrandečić wird erst drei Jahre spaeter veroeffentlicht werden. An ganz vielen Stellen betont Pollock, dass es total wichtig sei, irgendeine Lizenz anzugeben – das haelt sich leider an vielen Stellen bis heute und klebt uns als Bewegung am Bein.
Ueberhaupt, die ganze Idee von CKAN: Versionierung, Packages etc., wo sind wir 12 Jahre spaeter? Man denke nur an die RKI-Daten waehrend der Covid-Pandemie. Oder auch die gesamte Idee mit Dependencies und weiteren herunterzuladenden Datenpaketen. Die schmeckt ein wenig wie Linked Open Data – und ich haette das sehr gerne in der Praxis. Habe ich aber noch nie gesehen. (Bei 53:20 ff. wird das am Beispiel der Postleitzahlen beschrieben)
„Schaut mal, die Briten nehmen schon CKAN um Open Data zu veroeffentlichen und wir hoffen, dass das die deutsche Politik ueberzeugt, ebenfalls Open Data herauszugeben“. Ohweh, das tut weh.
Generell, die ganze Begeisterung – Daten werden wichtiger als Code werden, mit Gibson-Zitaten, etc.pp. – das haengt sicher auch mit meiner romantischen Vergangenheitsverklaerung zusammen, aber da kommt schon ein wenig Nostalgie auf 😉
Ab 44:36 kommt eine hervorragende Frage: Jetzt taucht da ein Katalog mit Daten auf – ist das langfristig nicht sowas wie es Webkataloge vor Websuchmaschinen waren? Sollte das nicht alles von Maschinen erfassbar und bearbeitbar sein anstatt haendisch? Pollock erklaert ein bisschen herum, aber in dem Austausch ist IMO ein Kernproblem der ganzen Datenportale bis heute sehr klar vorhergesehen.
Vor allem auch: Wer vertritt all diese Visionen heute ueberhaupt noch, um eher industriegetriebenen Memes wie dem „Datenraum“ etwas entgegenzuhalten? Wo bleibt das Zukunftsversprechen von Linked Open Data, so dass ich morgens nur einen Update-Befehl ausfuehren muss, um das (versionierte, aktuelle) Paket z.B. fuer die Impfdaten des RKI zu bekommen?
Im Sueden dauert ja alles ein wenig laenger, was das Netz angeht — moechte man meinen. Alles findet nur in Berlin statt — moechte man meinen. Dieses Wochenende haben wir einmal beschlossen, einfach mal dagegenzuhalten. Und das im beschaulichen Ulm. Sportlich, aber es scheint aufzugehen 😉
Zugegeben, die Runde war ueberschaubar. Und eigentlich mit weniger TeilnehmerInnen, als ich mir erhofft und erwuenscht hatte, was nicht zuletzt wegen der wirklich grandiosen Fruehstuecks- und Mittagsbuffets (Danke an die MFG und die Stadt fuer das Sponsoring!) und des spontan parallel gebackenen Apple Crumble schade war. Impulse gab es jedoch nicht zu knapp.
Eine Veranstaltung, bei der Internet und WLAN funktioniert ist keine richtige Veranstaltung. #occulm12
Erst einmal kam jedoch der Treppenwitz jeder Netzveranstaltung: Das WLAN ging nicht. Nach Telefoniererei mit dem kiz-Helpdesk stellte sich das als Copy&Paste-Problem heraus und es gab kurzerhand einen neuen Gastzugang. Danke an die uulm, bei der sowas auch wochenends funktioniert 😉
Ich bin nach dem ersten Tag auch ganz gluecklich ueber die Sessions. Meine persoenlich groesste Befuerchtung (noch vor der Teilnehmerzahl) als Barcamp-erst-Mitveranstalter war, dass am Ende nur langweilige Sessions auf dem Plan stehen wuerden. Dem war nicht so, und Barcamp-typisch ergaben sich auch abends noch viele Randdiskussionen.
Vorher kamen jedoch die eigentlichen Sessions, die von Einfuehrungen in Linked Open Data ueber das Apps4De-Gewinnerprojekt LISA, Praxisbeispielen aus Friedrichshafen, Verkehrsumfragen und freie Funknetze bis zum Austausch ueber den OpenData-Portal-Prototypen des Landes und Anwendungen im OPNV reichten. Alle Sessions mit mehr oder weniger vollstaendigen Mitschrieben finden sich in unserem EduPad (aktuell noch mit Zertifikatswarnung, sorry hierfuer)
Eines kann man auch nicht ohne Stolz sagen: Ulm und die Region sind am Ball. Genauer gesagt sind wir in der etwas absurden Situation, jeder Menge Offenheit und Bereitschaft zu Datenoeffnung zu begegnen, aber gar nicht genuegend EntwicklerInnen und AnwenderInnen zu haben, um auch praktisch aus allen Quellen machen zu koennen. Nicht zuletzt deswegen wollten wir hier auch die Keimzelle zu etwas weiterem Wachstum der datalove-Arbeitsgruppe (oder Daten-EinzelkaempferInnen) saeen.
Und wie immer ist ein Barcamp erst endgueltig vorbei, wenn keineR mehr Lust hat, noch dazubleiben. Momentan ist kurz nach 2300 Uhr, und hier sitzen nach dem Sofa-Abendausklang bei Apple Crumble immer noch Leute vor ihren Laptops und hacken Dinge.
An offenen Daten der Region koennen wir derweil momentan nicht allzuviel machen: Wenn schon das WLAN funktioniert, muss natuerlich tatsaechlich das OpenData-Portal des Landes ausfallen — in dem auch die Haushaltsdaten liegen, die ich gerne weiter aufbereitet haette. Mal sehen, ob wir die bis morgen irgendwie aufgetrieben bekommen.
Passenderweise faellt soeben das OpenData-Portal BaWue aus. @wi00194 ruft kurzerhand den T-Systems-Teamleiter an :> #occulm12

















{kind=link}