tl;dr vorneweg: Wir waren am Donnerstag beim DING-Verbund, am Freitag war ich beim VBB in Berlin, und die SWU geben ihre Fahrplaene als GTFS frei. Hurra!
DIVA-Allueren
Auf Einladung von Martin Schiller vom DING waren Fox und ich am Donnerstag beim DING als „unserem“ Nahverkehrsverbund zu Besuch und haben uns deren Software zeigen lassen. In Deutschland gibt es nur wenige grosse Player auf dem Markt fuer Fahrplanungs- und Auskunftssysteme, beispielsweise HaCon (HAFAS) und MentzDV (DIVA und EFA), wobei in BaWue hauptsaechlich DIVA fuer die Fahr-, Dienst- und Umlaufplanung und EFA fuer die elektronische Fahrplanauskunft zum Einsatz kommen.
Und wie das in einem kleinen Markt so ist, reissen die dazu gehoerenden Softwareloesungen nicht gerade vom Hocker. DIVA verwendet in Version 3 als Datenbackend nicht etwa einen Standard wie VDV-45X, sondern ein eigenes Textdateiformat, das ich auch nach laengerem Betrachten noch nicht so recht umrissen habe. In DIVA 4 soll wenigstens eine Datenbank im Hintergrund laufen, auf die neue Version seien bislang aber wohl nur wenige Verkehrsverbuende und -betriebe umgestiegen.
Verkehrsbetriebe benutzen solche Planungssoftware ohnehin erst ab einer bestimmten kritischen Groesse ihres Betriebs. Viele der kleineren Dienstleister verwenden entweder ganz andere Umlaufplanungssoftware, oder machen das gar von Hand oder in Excel. Der „einfache“ Transfer von DIVA zu DIVA kommt hier bei uns nur zwischen Stadtwerken und DING zustande, kleinere Anbieter auf dem Land schicken ihre Plaene im besten Fall per XLS, im schlimmsten in sonstigen semistrukturierten Formaten.
Eine weitere Hoffnung fuer den Export der Fahrplaene nach GTFS war, die Daten aus der Datenhaltung der Elektronischen Fahrplanauskunft (EFA) herauszubekommen. Die ist aber nicht minder… spannend. Die Dateien sehen wie Binaerblobs aus, und die EFA selbst ist ein Konglomerat zusammengeflanschter Module, die sehr nach historischem Wachstum aussehen. Die Echtzeitauswertung heisst beispielsweise „rud“ und lehnt sich damit noch ans Projekt RUDY an, das 2004 zu Ende ging. Und zwischendrin poppen auf dem Windows-Server-Desktop, auf dem die EFA laeuft, Adobe-Distiller-Fenster auf, wenn irgendjemand einen PDF-Fahrplan erstellt.
Spaetestens an der Stelle stellte ich mir dann schon die Frage, ob man mit geeigneten freien Software-Werkzeugkaesten nicht viel reissen koennte in diesem Orchideensektor 😀
Nichtsdestoweniger, der Ausflug war interessant, und zeigte auch, dass die CSV-Dateien, die wir von den Stadtwerken bekamen, genauso fuer den gesamten Verbund (und einigem haendischen Aufwand) aus DIVA exportiert werden koennten. Das waere aber tatsaechlich nicht unbedingt die Loesung, sondern vermutlich erst der Anfang weiterer Probleme, angefangen vom Unterschied zwischen Planungs- und Repraesentationsliniendarstellungen bis hin zu eindeutigen Schluesseln fuer Haltepunkte.
Ausflug zum VBB und endlich Ulmer GTFS-Daten 🙂
Tags darauf hatte die Open Knowledge Foundation zusammen mit dem Verkehrsverbund Berlin/Brandenburg (VBB) zur Projektvorstellung und Nachbesprechung des Hackdays im November 2012 eingeladen. Da unsere Arbeitsgruppe nach wie vor kein Reisebudget oder ueberhaupt irgendwelche Finanziers hat, hiess das also, um 0600 Uhr aufzustehen und mit dem Daumen nach Berlin zu reisen :>
Aufgrund meiner etwas unguenstigen Anreise (siehe Trampbericht unten) kam ich leider erst nach der ersten Projektvorstellungsrunde in den VBB-Raeumen am Bahnhof Zoo an, war aber sehr angetan vom grossen Andrang dort. Neben OKFN und VBB sassen dort Leute von der BVG, jemand von HaCon war eigens angereist, und ich konnte neben „alten Bekannten“ auch endlich mal Michael Kreil und anderen persoenlich die Hand schuetteln.
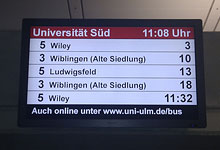
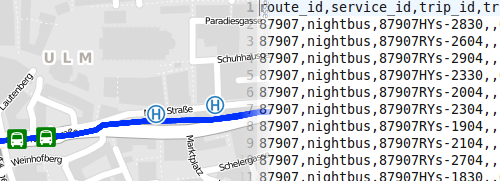
Eine ganz persoenliche Freude war mir, dort spontan eine Botschaft verkuenden zu koennen, auf die ich lange gewartet hatte: Auf der Anreise bekam ich den Link zum Datenauskunftformular der Stadtwerke Ulm zugeschickt, die wir nun ueber mehrere Monate lang begleitet haben, um ihre Soll-Fahrplaene nach GTFS zu exportieren. Leider mit einem Formular zum verpflichtenden Ausfuellen, aber das war ich dann doch durchaus bereit in Kauf zu nehmen, nachdem im Gegenzug die ODbL als Lizenz gewaehlt wurde 🙂

Es werden sich jetzt sicherlich nicht auf einmal™ tausende EntwicklerInnen auf den Ulmer Fahrplan stuerzen. Auch in Berlin passierten seit der Veroeffentlichung des VBB keine Instant-Wunder. Aber das ist meines Erachtens ein bedeutender Schritt und hoffentlich positive Signalwirkung fuer andere Verkehrsbetriebe, ebenfalls die Daten bereitzustellen.
Dementsprechend haben wir nach der Vorstellung das Ganze noch im OKF-Buero (siehe Bild) mit Mate und spaeter Bier begossen und uns noch solange darueber unterhalten, wie man das Thema weiter beackern koennte (wissenschaftliche Aufarbeitung, Hinweis auf das Kundenbindungspotenzial unabhaengiger Apps), bis ich endgueltig koerperlich so fertig war, dass ich mich endlich mit Gastgeber @_HeBu treffen musste, um unfallfrei ins Bett zu kommen.
(Das wurde dann durch einen Spaetibesuch und tags darauf durch einen Doener- und Spaeti-Besuch erfolgreich unterbunden. Trotzdem Danke, HeBu, fuer die neuerliche Gastfreundschaft und den ausgezeichneten Vanillequark von Butter-Lindner :D)
Trampstatistik
Hinweg:
- Abfahrt Rosengasse mit der Linie 4 um 0706 Uhr(?), Ankunft Eichenplatz 0716 Uhr, wo nix los war.
- Eichenplatz ab 0742 Uhr (26 Minuten) mit Margarete ehemals aus der Nachbar-WG, die anbot, mich generell unter der Woche immer um die Zeit auf die Lonetal nehmen zu koennen. Cool.
- Ankunft auf einer total verlassenen Lonetal Ost um 0759 Uhr. Erst an der Ausfahrt gestanden, dann angequatscht, trotzdem erst um 0900 Uhr weiter (61 Minuten). Dafuer im Geschaeftsauto im Tiefflug, 137 km in 67 Minuten.
- Kammersteiner Land Sued an 1007 Uhr, wenig los, angequatscht, 1047 mit 120 km/h und haeufigen Raucherpausen weiter (40 Minuten)
- Taktischen Fehler begangen, nicht waehrend der Mittagessenspause meiner Fahrerin in Frankenwald Ost einen neuen Lift zu suchen.
- Michendorf Süd an 1605 Uhr, machte mal eben 5:18h fuer 408 km. Trotz guter Unterhaltung etwas schade.
- Weiter um 1620 (15 Minuten) bis zur U Kurfuerstenstrasse um 1710 Uhr, Fussmarsch bis zum Bf Zoo/VBB.
Rueckweg:
- Aufbruch bei HeBu mit der S1 ab Wollankstrasse um 1313, S Johannissee an 1400 Uhr. An der Grunewald erst ein wenig rumgeschaut und angequatscht, das lief aber nicht. Also um 1430 mit Schild „Muenchen A9“ ab auf die Rampe, 1440 Lift bekommen 🙂
- Fraenkische Schweiz/Pegnitz West an 1730 Uhr, d.h. 362 km in 2:50 Minuten und hervorragender Unterhaltung waehrend der Fahrt ueber die Unterschiede zwischen PaedagogInnen und ErzieherInnen 😀
Sanifair-Gutscheine gegen Burger getauscht, 1750 mit Schild „Ulm“ an die Ausfahrt gestellt, 1804 Lift bis Bahnhof Heidenheim angeboten bekommen. Da sagt man nicht nein 🙂
- Bf Heidenheim an 1942, 197 km in 1:38h. Das waren rekordverdaechtige 5:12h von Grunewald bis Heidenheim, und selbst mit S-Bahn vorneweg und den 50 Minuten Regionalexpress nach Ulm am Ende gerade mal 45 Minuten langsamer als ein ICE gewesen waere 😀