Wie gestern erzaehlt, hatte ich mich beim Hackday Moers ja mit den Verkehrsmessdaten der Stadt Moers beschaeftigt. Die liegen als CSV-Export vor und umspannen jeweils einen Zeitraum von 48 Stunden – gemessen mit einer dieser Boxen, die am Strassenrand aufgestellt werden, und Geschwindigkeit, Fahrtrichtung und Laenge des Fahrzeugs erfassen. So sieht sowas aus:
14.05.13 07:39:33;00;030;07;0
14.05.13 07:39:35;00;030;04;0
14.05.13 07:39:37;00;027;04;0
14.05.13 07:40:52;00;024;07;0
14.05.13 07:40:53;00;024;07;1
14.05.13 07:41:39;00;035;01;0
In der ersten Spalte kommt ein Zeitstempel, gefolgt von einem Platzhalter (00), der Geschwindigkeit in km/h, der Fahrzeuglaenge in Metern und der Fahrtrichtung. Auf den Beschreibungsseiten gibt es noch Hinweise zur Klassifizierung der Fahrzeuge nach der Laenge, und Angaben zum Dateinamen (Name der Messstelle und vorgeschriebene Hoechstgeschwindigkeit).
Ich habe das zum Anlass genommen, die nicht sonderlich uebersichtlichen Rohdaten grafisch in R mit ggplot2 aufzubereiten. Cave: Ich bin kein Statistiker, und auch kein R-Crack – das Ergebnis kam durch strategisches Googeln und Ausprobieren von Codeschnipsel zusammen mit dem Lesen der R-internen Dokumentation zustande, und war vor allem auch eine prima Gelegenheit, meine eingerosteten R-Faehigkeiten wieder aufzufrischen. Pull-Requests fuer Verbesserungen sind gerne gesehen 😉
Daten einlesen
Um die Daten zu analysieren, muessen sie natuerlich erst einmal eingelesen werden. Das geht recht fix – Separator fuer die CSV-Spalten ist das Semikolon, und da die Datei ohne Spaltenueberschriften kommt, wird header=FALSE gesetzt:
endstr <- read.csv("endstrasse_17_t50_03112014.txt",header=FALSE,sep=";")
names(endstr) <- c("date","place","tempo","length","direction")
Danach werden mit names() die passenden Spaltenueberschriften gesetzt.
Das reicht schon, um eine erste Auswertung zu machen:
summary(endstr)
date place tempo length
03.11.14 10:56:07: 2 Min. :0 Min. :12 Min. : 1.000
03.11.14 12:42:34: 2 1st Qu.:0 1st Qu.:37 1st Qu.: 2.000
03.11.14 16:44:23: 2 Median :0 Median :42 Median : 3.000
03.11.14 16:44:30: 2 Mean :0 Mean :42 Mean : 3.512
04.11.14 10:03:37: 2 3rd Qu.:0 3rd Qu.:47 3rd Qu.: 4.000
04.11.14 11:17:40: 2 Max. :0 Max. :89 Max. :43.000
(Other) :2723
Das ist schon einmal ein aufschlussreicher erster Blick: Der Median der Geschwindigkeit ist 42 km/h – und nur ein Viertel der Messungen lag bei 47 km/h oder mehr.
Das laesst sich auch in einem Histogramm fuer die Geschwindigkeit auswerten:
jpeg('endstr_histo.jpg')
hist(endstr$tempo)
dev.off()
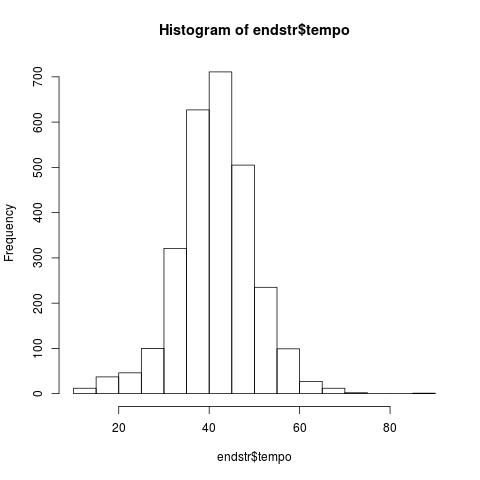
Schoen ist natuerlich anders 😀
Ausgabe als Scatterplot
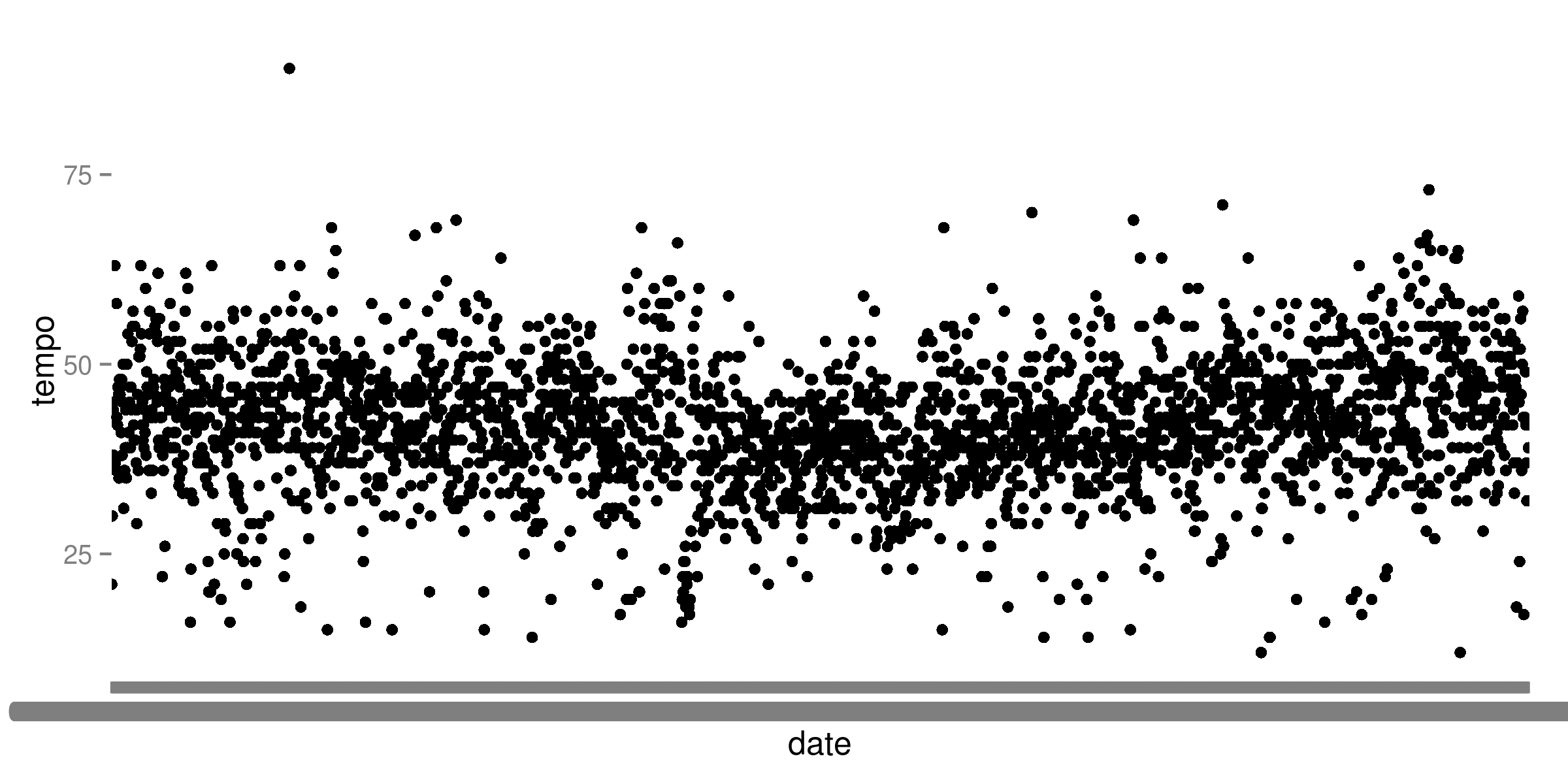
Passender waere, die Messung als Scatterplot ueber die Zeit hinweg auszugeben. Mein erster Ansatz analog zum unlaengst hier verlinkten Tutorial war ein wenig naiv:
library(ggplot2)
ggplot(endstr, aes(x=date, y=tempo)) +
geom_point()
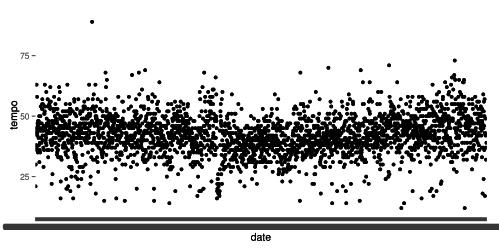
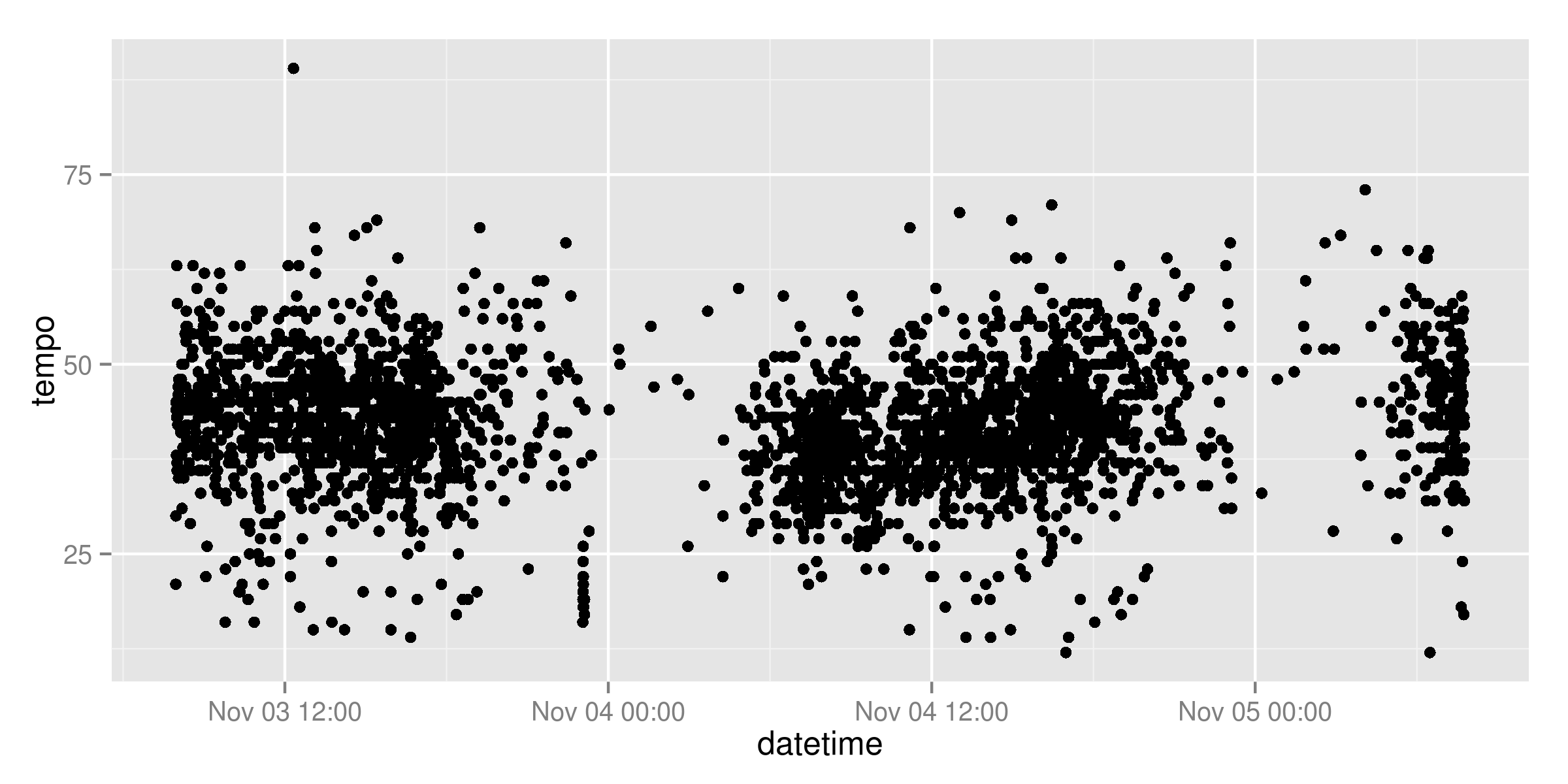
Na, wem faellt auf, was da nicht stimmt? Klar, die Zeitpunkte werden nicht als Zeit interpretiert, sondern gleichverteilt auf der X-Achse aufgetragen. Ich habe am Anfang ein wenig herumgebastelt, das bei der Auswertung in POSIX-Zeit umzuwandeln, letztlich war aber die sinnvollere Variante, einfach die Tabelle um einen „richtigen“ Zeitstempel zu erweitern:
endstr$datetime <- as.POSIXct(endstr$date,format="%d.%m.%y %H:%M:%S")
ggplot(endstr, aes(x=datetime, y=tempo)) +
geom_point()
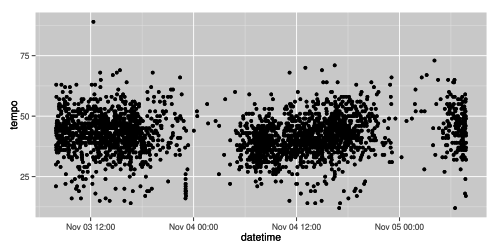
Schon besser 🙂 Analog habe ich auch fuer die Fahrzeuggroesse und die Tempoabstufungen Klassen angelegt – bei der Fahrzeuggroesse analog zur Klassifizierung in der Dateibeschreibung der Stadt, bei der Geschwindigkeit bis zum Tempolimit, bis 6 km/h ueber dem Tempolimit, und mehr als 6 km/h zu schnell:
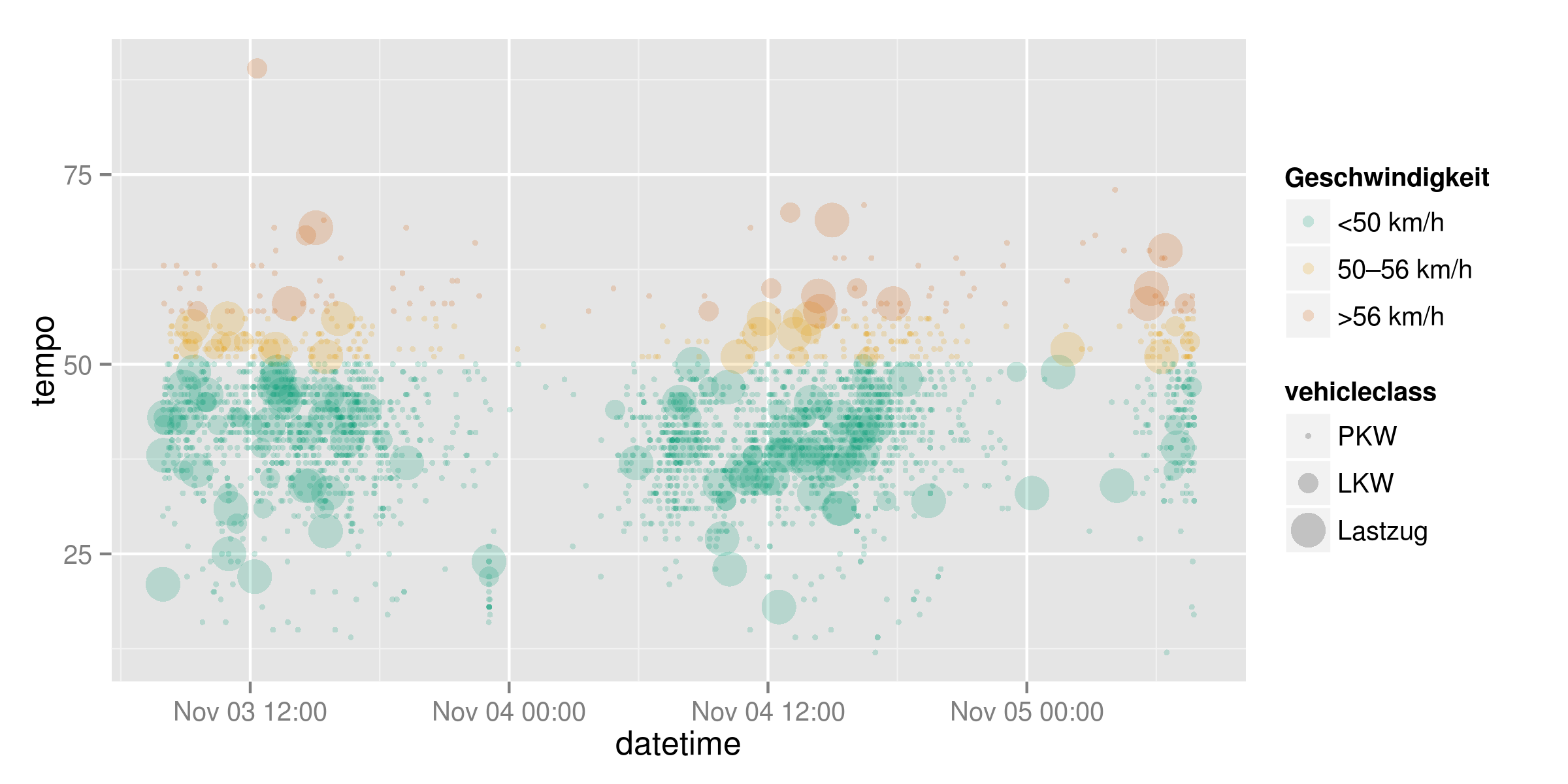
endstr$tempoclass <- cut(endstr$tempo, breaks = c(0,50,56,Inf), labels=c("<50 km/h", "50–56 km/h", ">56 km/h"))
endstr$vehicleclass <-cut(endstr$length, breaks = c(0,8,12, Inf), labels=c("PKW", "LKW", "Lastzug"))
Einfaerben!
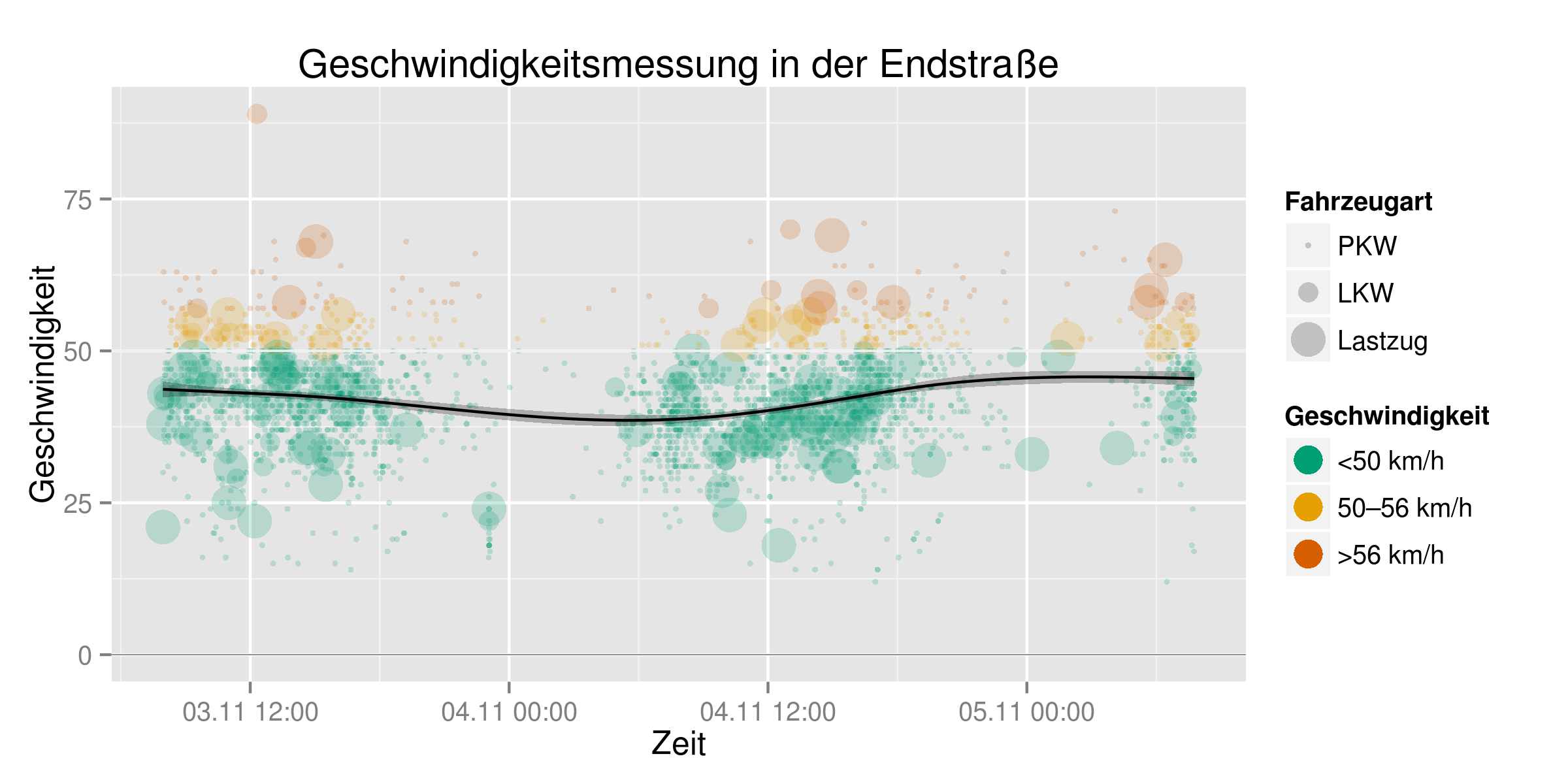
Mit diesen Daten lassen sich nun die einzelnen Punkte auch einfaerben. Ich habe die Punkte semitransparent gemacht, damit die Faerbung an den Haeufungen intensiver wird, und die Groesse anhand der Fahrzeugklasse gewaehlt. Fuer die Farben der Geschwindigkeitsklassen habe ich ein Pseudo-Rot-Gelb-Gruen-Schema gewaehlt, das auf eine fuer Farbenblinde taugliche Farbpalette zurueckgreift.
ggplot(endstr, aes(x=datetime, y=tempo, colour = tempoclass)) +
geom_point(alpha=0.2, aes(size=vehicleclass)) +
scale_color_manual(values= c("#009E73", "#E69F00", "#D55E00"), name="Geschwindigkeit")
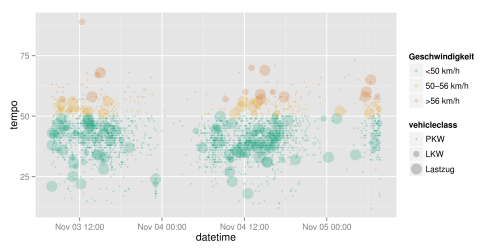
Feinanpassung
Ein wenig fehlt noch: Die Achsen und das Diagramm muessen noch richtig beschriftet werden: Die Zeitachse sollte ein im deutschen Sprachraum „passend“ lesbares Zeitformat bekommen, und in der Legende sollten die Punkte und ich wollte auch gerne eine Trendlinie sowie eine Hilfslinie bei der „richtigen“ Geschwindigkeit haben. Die Datumsformat-Umformatierung ist in library(scales) zu finden. Die Farben in der Legende sollten ausserdem nicht transparent angezeigt werden, das geht mit override_aes.
Fuer die Trendlinie habe ich den Tipp aus dem vorher verlinkten Tutorial verwendet, die ein Generalized Additive Model verwendet – ich habe keinen blassen Schimmer, ob das passt, aber es sieht zumindest fuer Semilaien wie mich passend aus 😉
Der komplette Code fuer den Graphen samt Ausgabe als PNG sieht nun so aus:
library(ggplot2);library(scales);library(Cairo);
ggplot(endstr, aes(x=datetime, y=tempo, colour = tempoclass)) +
# Punkte sind semitransparent, Größe abhängig von der Fahrzeugklasse
geom_point(alpha=0.2, aes(size=vehicleclass)) +
scale_color_manual(values= c("#009E73", "#E69F00", "#D55E00"), name="Geschwindigkeit") +
# Hilfslinie bei 50 km/h
geom_hline(yintercept=50, size=0.4, color="#efefef") +
# Hilfslinie auf dem Nullpunkt der Y-Achse
geom_hline(yintercept=0, size=0.1, color="black") +
# Trendlinie mit Generalized Additive Model, siehe http://minimaxir.com/2015/02/ggplot-tutorial/
geom_smooth(alpha=0.25, color="black", fill="black") +
# Achsenbeschriftungen
labs(title="Geschwindigkeitsmessung in der Endstraße", x="Zeit", y="Geschwindigkeit", size="Fahrzeugart") +
guides(colour = guide_legend(override.aes = list(size=5 ,alpha=1))) +
scale_x_datetime(labels = date_format("%d.%m %H:%M"))
ggsave("endstr_final.png", width=8, height=4, dpi=300, type="cairo-png")
Mit library(Cairo) funktioniert die Transparenz auch bei der Bildausgabe wenigstens leidlich. Ich musste dazu libcairo-dev installieren (mehr Informationen dazu hier und hier)
Und voila – so sieht's aus:
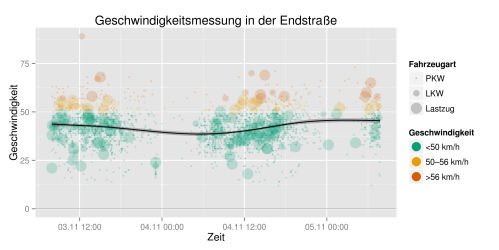
Juka spielt gerade noch nebenher mit Leaflet herum, um die Graphen auch zu kartieren – die gesamte Ausgabe ist derweil auf Github anzusehen.