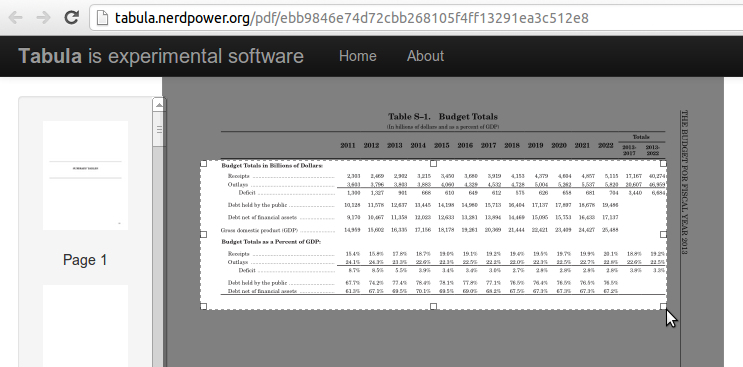
Im Maerz 2020 warb ich hier dafuer, dass die oeffentliche Hand Kompetenzen aufbauen muesse, um Software auch verstehen zu koennen. Das heisst unter anderem auch Abhaengigkeiten verstehen, Sicherheitsparadigmen, und sei es im Zweifel nur, um passende Auftraggeberkompetenzen zu haben.
Nachdem die geschaetzten Wesen des IT-Sicherheitskollektivs Zerforschung neulich die Hausaufgaben-Verkaufs-App learnuu zerlegt hatten, gab es im Anschluss einen Twitter-Space mit ueber 200 Menschen, in dem die Geschichte noch einmal erzaehlt und das interessierte Fachpublikum Fragen stellen konnte. Zwei Dinge wollte ich dazu gerne kurz festhalten, nachdem mir eben ein Twitter-Thread dazu ueber den Weg lief.
Immer wieder entdecken Ehrenamtliche wie @zerforschung Sicherheitslücken in Lern-Apps, durch die Daten von Kindern ungeschützt sind. Letzter Fall: #Learnu. Das hat auch mit Systemversagen zu tun. Thread ⬇️ (1/9)
— Christian Basl (@ChristianBasl) November 14, 2021
Die Zivilgesellschaft muss es richten
Zum Einen: Ich finde die Leistung von Zerforschung – und auch all der anderen, die irgendwelchen Startups hinterherkehren – sehr beachtenswert, und zwar in mehreren Dimensionen. Man muss sich das einmal vorstellen: Da sitzen ein paar junge Leute im Pandemiefrust ueber Deutschland verteilt zusammen, verbunden durch Messenger-Chatgruppe und BBB-Videocalls. Und waehrend sie eigentlich mal LED-Lampen aus Fernost zerforschen wollten, stolpern sie nun seit Monaten immer wieder gegen irgendwelche Testzentren oder sonstige IT-Infrastruktur, und aus einer Mischung aus Neugier, dem Wissen um die richtigen Werkzeuge, Schabernack und Koffein entdecken sie dabei eine broeselige Infrastruktur hinter der schicken Fassade nach der anderen. Upsi!
Die ganz andere Dimension ist aber, wenn man sich bewusst macht, wer solche Probleme denn sonst aufdecken wuerde. Derzeit basiert die Ueberpruefung irgendwelcher deutscher IT in der Wildbahn – egal ob privatwirtschaftlich auf den Markt gebracht oder von der oeffentlichen Hand beauftragt – in einer beachtlichen/bedenklichen Anzahl der Faelle darauf, dass spassorientierte Menschen auf Mate damit an einem langsamen Samstagabend in Quarantäne Karussell zu fahren versuchen. Die zustaendigen Behoerden werden meist nur reaktiv – also auf Beschwerden hin – taetig, und das BSI leidet seit Jahren unter dem Schatten, keine unabhaengige Einrichtung sondern nachgeordnete Behoerde des Innenministeriums zu sein.
Egal ob Testzentrum oder Hausaufgaben-Vercheck-App: es scheint also tatsaechlich vielfach daran zu liegen oder zu scheitern, dass zivilgesellschaftliche Akteure genuegend Kentnnisse und Freizeit haben, solche Tests zu machen. Das muss man einfach mal sacken lassen.
Zertifikate vom IT-Planungsrat?
Die andere Sache fiel mir aber auf, als im Twitter Space ueber moegliche Zertifizierung von Software diskutiert wurde, und wie/ob man IT irgendwie pruefen lassen sollte. Weil, so schick und gut ich es faende, wenn Sicherheitstests (vor allem dann, wenn schon einmal schief anschauen reicht) nicht von Menschen in ihrer Freizeit abhaengen wuerden: Ich fuerchte mich ein wenig vor einer Welt, in der solche Zertifikate zu aehnlich religioesen Ersatzhandlungen verkommen wuerden wie die Aufstellung eines Verfahrensverzeichnisses um das passende Haekchen wegen der DSGVO machen zu koennen. Oder in der dieselben Menschen definieren, was „sicher“ ist, die sich den ganzen Prozess rund ums OZG ausgedacht haben.
Denn, auch die oeffentliche Hand, auf allen foederalen Ebenen, beschafft oder finanziert Software. Bisweilen auch mal, um den Eindruck zu erwecken, man taete ja etwas, beispielsweise in einer Pandemie. Und selbst wenn man ein erweitertes Set als die bisherigen Pruefschablonen haette, muesste man diese auch anzuwenden und zu interpretieren verstehen. In der Realitaet muss man lange suchen, dass die oeffentliche Hand bei der Begutachtung von Software die richtigen Fragen stellt – oder andersherum, dass an den entscheidenden Ebenen Input wie der von Zerforschung auch geparst werden koennte.
Mehr Fragen als Antworten
Im Wikimania-Vortrag “Wikimedia Movement and the Paradox of Open” (via @kommunikonautin) nannte einer der Vortragenden die ehrenamtliche Arbeit an Wikipedia und Freiem Wissen eine burgeoise Art des Aktivismus: Einer Wissens- und Zeitelite deutlich zugaenglicher als dem Rest der Menschheit. Dasselbe gilt fuer all die anderen Freizeit-nebenher-Aktivitaeten, egal ob Sicherheitsforschung, Arbeit an Freier/Open-Source-Software, Lobbyarbeit dafuer oder die Geschichten einzusammeln, die ausserhalb der unmittelbaren eigenen Blase in diesen Themen passieren.

Mit Verweis auf XKCD 2347 (oben) gibt es beispielsweise in der Freien-Software-Welt ueber die Jahre hinweg immer mehr Stimmen, die die oeffentliche Foerderung solcher Softwareprojekte fordern. Das finde ich prinzipiell gut, nur: Was hiesse das, konsequent zu Ende gedacht? Sollte dann nicht auch Drive-by-Gegentreten gegen marode Apps gefoerdert werden? Oder Beitragen zu Wikipedia? Oder zu Wikidata, als Basis aller moeglicher kommerzieller Sprachassistenten? Und, falls ja: Wie? Mit Marktmechanismen? Und im Vertrauen bei der Vergabe der Mittel auf genau die Politik und Verwaltung, die einen all die Jahre nie so wirklich verstanden zu haben scheint, was aber egal ist, Hauptsache ein bissel Foerderung verteilt?
Und – daraus kam der Querverweis zum urspruenglichen Artikel, und daran haengen z.B. solche Foerderentscheidungen – wie zum Teufel bekommen wir denn nach ueber einem Jahrzehnt Civic Tech in Deutschland die Behoerden und politischen Apparate selber auf den notwendigen Stand?
Ich bin ratloser denn je.