Die Digitalisierung des Gesundheitswesens ist ein Trauerspiel. Die Datenlage zu den Auswirkungen der Omikron-Welle ist ein Desaster. Dabei ist eine gute Datenlage der Dreh- und Angelpunkt im Kampf gegen Omikron, kommentiert Eva Quadbeck. https://t.co/UhTLwZHdN7
— RND (@RND_de) January 23, 2022
Die Digitalisierung des Gesundheitswesens sei ein Trauerspiel, titelt das Redaktionsnetzwerk Deutschland. Nachdem man dem Reflex nachgegeben hat, „was, nur des Gesundheitswesens?“ zu rufen, dachte ich mir, man koennte ja mal das mit dem Aufschreiben des besseren Gegenentwurfs machen, der mir seit Monaten im Kopf rumspukt.
Tatsaechlich beobachte nicht nur ich die (Daten)lage seit geraumer Zeit mindestens mit Irritation. Lena Schimmel schrieb kurz vor Weihnachten einen ganzen Thread, dass sie selbst erschreckend lange die eigentlich vom RKI veroeffentlichten Daten ueber Sequenzierungen gar nicht erst gefunden hatte:
Okay, das ist jetzt… peinlich? Lustig? Beruhigend? Beunruhigend? Irgendwie alles davon:
— Lena Schimmel (@LenaSchimmel) December 23, 2021
Ich hab ja kürzlich die Sequenzierungen des RKI auf GitHub gefunden und viel Arbeit hinein gesteckt, aus den Sequenzen die Varianten zu bestimmen.
Zeigt sich: die stehen da schon drin. Jap.
Ich glaube, dass „wir“ als „die gesellschaftliche Open-Data-Lobby“ uns wieder viel viel mehr auf Linked Open Data als Ziel konzentrieren und das auch kommunizieren muessen. Bei all dem Einsatz, wenigstens CKAN oder irgendein Datenportal auszurollen, scheint das fernere Ziel ueber die Jahre immer mehr in Vergessenheit geraten zu sein.
Schon vom Nutzungsfaktor her duerfte dieses Ziel jedoch am Beispiel der Pandemie sehr klar zu vermitteln sein. Seit nun beinahe zwei Jahren setzen sich jeden Morgen viele DatenjournalistInnen an ihre Rechner und versuchen, aus den aktuellen Datenpunkten zum Infektionsgeschehen und den Impfungen Erkenntnisse zu ermitteln und diese nachvollziehbar aufzubereiten.
heute arbeite ich eigentlich nicht, aber das @rki_de fügt unnötige spalten ein, deren werte sich aus den vorhandenen daten berechnen lassen. pic.twitter.com/8uT9GarRzt
— yetzt (@yetzt) April 9, 2021
Ueber die Zeit hinweg ist es ein bisschen zu einem Running Gag geworden, dass das RKI dabei immer wieder mal Spalten vertauscht oder neue Daten hinzufuegt, so dass all die gebauten Parser auf die Nase fallen.
{kind=link}
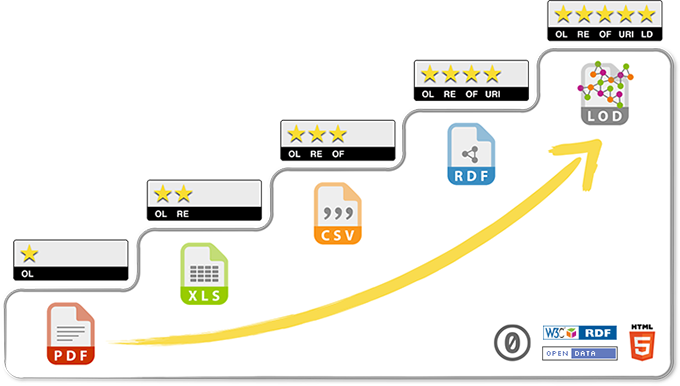
Derweil koennte die Lage mit verlinkten – oder wenigstens semantischen – Daten deutlich einfacher ablaufen. Man kann sich die 5-Sterne-Treppe fuer offene Daten am Beispiel der RKI-Berichte recht anschaulich klarmachen:
- In der ersten Stufe (die Daten sind irgendwie da) sind die Informationen zwar irgendwie als digitale Symbole codiert, das kann aber auch ein PDF sein, oder im schlimmsten Fall ein PDF eines eingescannten Dokuments. Eine Maschine kann diese Symbole uebertragen und die dadurch codierten Inhalte aufbereiten und anzeigen, aber die Datenpunkte darin sind im unpraktischsten Fall nur fuer Menschen lesbar.
(Exkurs. Wenn wir ueber „Daten“ sprechen, werden schon diese beiden Definitionen haeufig wild durcheinander geworfen. Einerseits die Symbole oder „bits und bytes“, die Information codieren – so wie die Buchstaben, die diesen Satz bilden. Andererseits Datenpunkte, die z.B. verarbeitbare Information ueber einen Temperaturmesswertverlauf abbilden.)

- In Stufe 2 und 3 sind auch die Datenpunkte fuer Maschinen interpretierbar, weil die Informationen mehr oder weniger strukturiert in einem proprietaeren (Excel) oder offenen (CSV) Format vorliegen. Die Zusammenhaenge bzw. die Semantik erschliessen sich jedoch immer noch nur der menschlichen Betrachterin, die diese Struktur selbst in die automatisierte Auswertung einbauen muss. Wenn das RKI ohne Ankuendigung die Reihenfolge der Spalten aendert, kann ein einmal geschriebenes Auswertungsskript diese Aenderung nicht ohne weiteres erkennen und wird erst einmal falsche Auswertungen ausgeben, bis es auf die veraenderte Datenlage angepasst ist.
- Das ist der Punkt, der in Stufe 4 behoben wird: Dann ist naemlich auch die Semantik als weitere Ebene im Datensatz codiert. Ich muss nicht mehr als auswertende Person aus dem Originaldokument in menschlicher Sprache lesen und dann fuer das Auswertungsskript festlegen, dass Spalte B das Bundesland und Spalte N die Zahl der in einem Impfzentrum vollstaendig geimpften Personen unter 60 Jahren ist. Ich muss stattdessen dem Auswertungsskript fuer das (zugegeben, einfachere) Beispiel des Bundeslands „nur“ mitgeben, dass es in irgendeiner Spalte eine Beschreibung gemaess Language, Countries and Codes (LCC) erwarten kann, und da wird dann ein passender ISO-3166-2-Code mit dabei sein. In welcher Reihenfolge die Spalten dann ankommen, und ob das jetzt der Impf- oder der Inzidenzbericht ist, spielt eigentlich keine Rolle mehr.
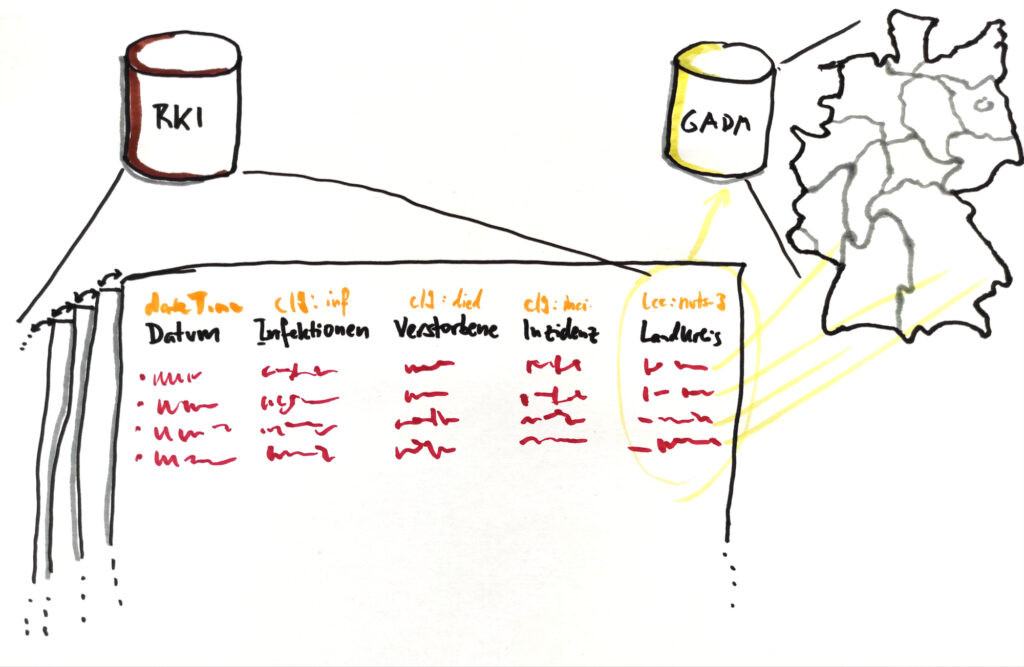
Im Vollausbau der Stufe 5 verlinkter Daten wird vielleicht am besten deutlich, was man mittlerweile haben koennte. Anstatt dass man sich jeden Morgen ein hoffentlich aktualisiertes Excel-File der Inzidenzen und Impfinformationen herunterlaedt, reicht das Gegenstueck zu einem git pull – alles liegt als von Tag zur Tag (bzw Veroeffentlichungsschnappschuss zu Veroeffentlichungsschnappschuss) versionierter Datenframe vor. Wenn ich den Datensatz einmal ausgecheckt habe, kann ich lokal die Updates bekommen, die Unterschiede von Schnappschuss zu Schnappschuss diffen, und auch in der Historie beliebig zurueckspringen, um Zeitreihen zu machen.
Da aber sowohl die Semantik im Datensatz codiert ist, als auch Links auf andere Datenquellen vorhanden sind oder von mir hergestellt werden koennen, kann ich sehr viel mehr automatisieren, was ich sonst zu Fuss machen muesste: Wenn in irgendeiner Spalte die Landkreise mit Kreisschluessel codiert sind, und ich meine Auswertung per Karte machen will, kann ich aus einer passenden anderen Datenquelle automatisch die Geometrien des NUTS-3-Level in Deutschland laden und mit dem RKI-Datensatz verknuepfen.
Das ist jetzt rein aus der Nutzungsperspektive gesehen, weil das mit die anschaulichste ist. Eigentlich viel spannender ist aber, die Konsequenzen durchzudenken, was es bedeuten wuerde, die dafuer notwendige Infrastruktur im Betrieb zu haben. Das heisst, dass Datenpunkte und Informationen nicht haendisch in der Gegend herumgetragen und zu Fuss alleine in Excellisten vorgehalten und gepflegt werden. Dass es definierte Schnittstellen und Datenfluesse gibt, die auch die behoerdeninterne Nutzung von fuer Entscheidungen relevanter Daten erlauben, ohne dass diese muehsam und fehleranfaellig zusammengekratzt werden muessen. Und nicht zuletzt auch, dass wir dafuer die ueber Jahrzehnte aufgebauten technischen Schulden der oeffentlichen IT-Infrastruktur abgebaut und die Architektur vorausschauend sparsamer weil effizienter(!) geplant und umgesetzt haben.
Es ist total schade, dass so viele der Visionen aus den 2000ern durch das jahrelange Klein-Klein der Umsetzung, die zu schliessenden Kompromisse mit Verwaltungen, und die perverse incentives fuer „Umsetzungen“ verkaufende Dienstleister so tief in die metaphorischen Sofaritzen verschwunden und in Vergessenheit geraten sind.
The current public funding schemes geared towards “digitalization” and “innovation” constitute perverse incentives. In the long run, they are not only expensive, but will pile up massive amounts of technical debt vastly exceeding the investments. https://t.co/dsb8ovKMvq
— stefan (@_stk) January 29, 2022
Manches davon ist natuerlich auch mittlerweile ueberholten Ueberlegungen von damals geschuldet. In der 5-Sterne-Treppe wird beispielsweise als erster Schritt ein „OL“ angegeben, das fuer eine Offene Lizenz stehen soll. Das halte ich mittlerweile fuer ueberholt und teilweise durch die viele Wiederholung auch ein wenig schaedlich. Denn die Diskussion z.B. bei Infektions- oder Impfdaten ist eigentlich gar nicht, ob sie unter der internationalen Creative-Commons-Lizenz oder der nutzlosen und ersatzlos abzuschaffenden Datenlizenz Deutschland „lizenziert“ werden. Denn das sind Faktendaten, und die gehoeren allesamt gemeinfrei gemacht.
tl;dr: Bitte einmal Linked Open Data als Ziel, zum mitnehmen, und etwas mehr freundliche Radikalitaet.